Branch 設計筆記¶
這份是給 maintainer 看的內部文件,不是讀者面向的內容。
5 個 branch 怎麼分、entry 怎麼判斷該放哪、什麼時候要不要新開 branch——這些設計決定的記錄。新 maintainer 接手時看這份就懂為什麼是這樣分。
為什麼是 5 個 branch(不是 3 個或 10 個)¶
Branch 跟 Track 的關係¶
5 條 branch 設計成 兩條軌道走完都接得上: - Track A 完成 A3 → 從 branches 選一條繼續 - Track B 完成 Stage 7 → 從 branches 選一條繼續 - Branch entry 的 curation 標準不依軌道區分——同一個工具不論是 Track A 用法(用現成 CLI)還是 Track B 用法(自己接 SDK),都放在對應 audience 的 branch 內
例外:for-everyday-users branch 可以直接進入——不一定要走完軌道。這條 branch 的目標讀者是「Claude.ai / ChatGPT 重度使用者,想用 AI 但不一定想 build」,他們可能根本不需要碰 Track A 或 B;branch 內也明確標示「不一定要走完整條主幹」。其他 4 條 branch(researcher / developer / teacher / knowledge-worker)預設讀者已走完一條軌道。
Branch maintainer 應該意識到:進來看 branch 的讀者背景可能差很多——剛走完 Track A 的人對 framework 內部不熟、剛走完 Track B 的人對 CLI 操作可能不熟、直接進 everyday-users 的人對 Stage 0-2 都可能跳過。Branch entry 的 prose 要盡量讓這幾種讀者都看得懂。
太少(≤3)的問題¶
3 個會強行把多個 audience 塞同一條,譬如「professional」涵蓋 dev + researcher + knowledge worker——但他們的 pain point 完全不同。研究者要 grounded citation,開發者要 git-native,知識工作者要 email triage——硬擠成一條 branch 會讓 entry 互相 dilute。
太多(≥7)的問題¶
audience 切太細會: - 每個 branch 都很薄(沒幾個 entry),讀者覺得不被照顧 - 邊界開始模糊(資料科學家 vs 機器學習工程師?產品經理 vs 顧問?) - maintain 成本變高(要看的 branch 變多)
5 是 sweet spot¶
4 個職業(research / dev / teach / knowledge work)覆蓋大部分專業場景;第 5 個 everyday users 收尾「不寫 code 的純使用者」這條沒被任何職業 branch 照顧到的 audience。
判準:每個 branch 都應該對應到一個讀者一秒就能自我認領的身份標籤。如果 maintainer 自己都要想 30 秒才能決定一個 entry 該放哪,就是 branch 切得不夠清楚。
5 個 audience 的核心 pain point¶
每個 branch 都是回應一個具體 pain,不是涵蓋一整個職業生涯:
| Branch | 核心 pain | branch 主要回應 |
|---|---|---|
| 🔬 研究人員 | 「我要 review 100 篇 paper、寫 lit review,但時間不夠」 | 文獻 RAG、Outline-driven 寫作、Zotero 整合 |
| 💻 開發者 | 「我有 10 個 PR 要 review、每個 codebase 都不同 convention」 | git-native CLI、IDE coding agent、code review skill |
| 🎓 教師 | 「備課要花 4 小時、我手上的 prompt 都太通用」 | 學科特化 prompt、課程素材、評量自動化 |
| 📊 知識工作者 | 「每天信箱 100 封、會議紀錄要轉成 action items、隔天還要寫 weekly report」 | Email triage、會議紀錄、自動化 workflow |
| 👥 日常使用者 | 「我不寫 code,但想用 AI 改善生活,不知道從哪開始」 | Tier 0 入門到 Tier 2 進階 CLI 的階梯式路線 |
每個 branch 的 entry 選入都應該回到「能不能解決核心 pain」這個問題。如果不能,就是 entry 該放別的地方。
Branch 之間的邊界¶
判斷一個 entry 該放哪個 branch,按這 3 條判準依序考慮:
1. 主要 user persona¶
看上面 pain table——這個 entry 解決的是哪一個 audience 的 pain?通常很清楚。
2. 預期動手程度¶
不寫 code 的工具 → 偏 everyday-users / knowledge-worker。CLI / SDK 工具 → 偏 developer。介於中間(譬如 ChatPaper 是命令列但對研究者友善)→ 看 #1 主要 persona。
3. 應用場景¶
同一個工具在不同場景下歸類不同。例如: - Ollama:給 everyday-users 是「隱私場景跑本地 LLM」(Tier 3),給 developer 是「開發 agent 的本地測試 backend」——但這份 catalog 把它放在 Stage 1(基礎設施層級),各 branch 從那裡引用。 - f/awesome-chatgpt-prompts:放 for-teacher(給教師當教材參考)、也放 for-everyday-users(不寫 code 也能用的 prompt 庫)。
灰色地帶處理(同一 repo 出現在多 branch)¶
規則:同一 repo 可以在多 branch 出現,但每處要有不同的 framing(適合誰、教什麼)。推薦星等預設一致——同一個工具的客觀價值不會因 audience 改變;除非有明確的 audience-specific 理由(譬如「進階度差太多」),且寫進 Notes 解釋。詳見 resources/style-guide.md 2。
範例:
- obra/superpowers 出現在 Stage 5、for-developer、for-knowledge-worker、for-teacher
- Stage 5:作為 SKILL.md collection 範例
- for-developer:作為 TDD / debug skill 來源
- for-knowledge-worker:作為腦力激盪 / 規劃 skill
- for-teacher:作為通用寫作 skill
- 4 處都是 ⭐⭐⭐⭐(這是規則的正例:framing 不同、評等一致)
反例(不該這樣做):
- kaixindelele/ChatPaper 只放 for-researcher,不放 for-everyday-users。原因:它是研究者專用流程(總結 / 翻譯 / 審稿回覆),everyday user 用不到也不該被推。
兩種 entry 結構:tier vs flat¶
Tier 結構(目前只用在 for-everyday-users)¶
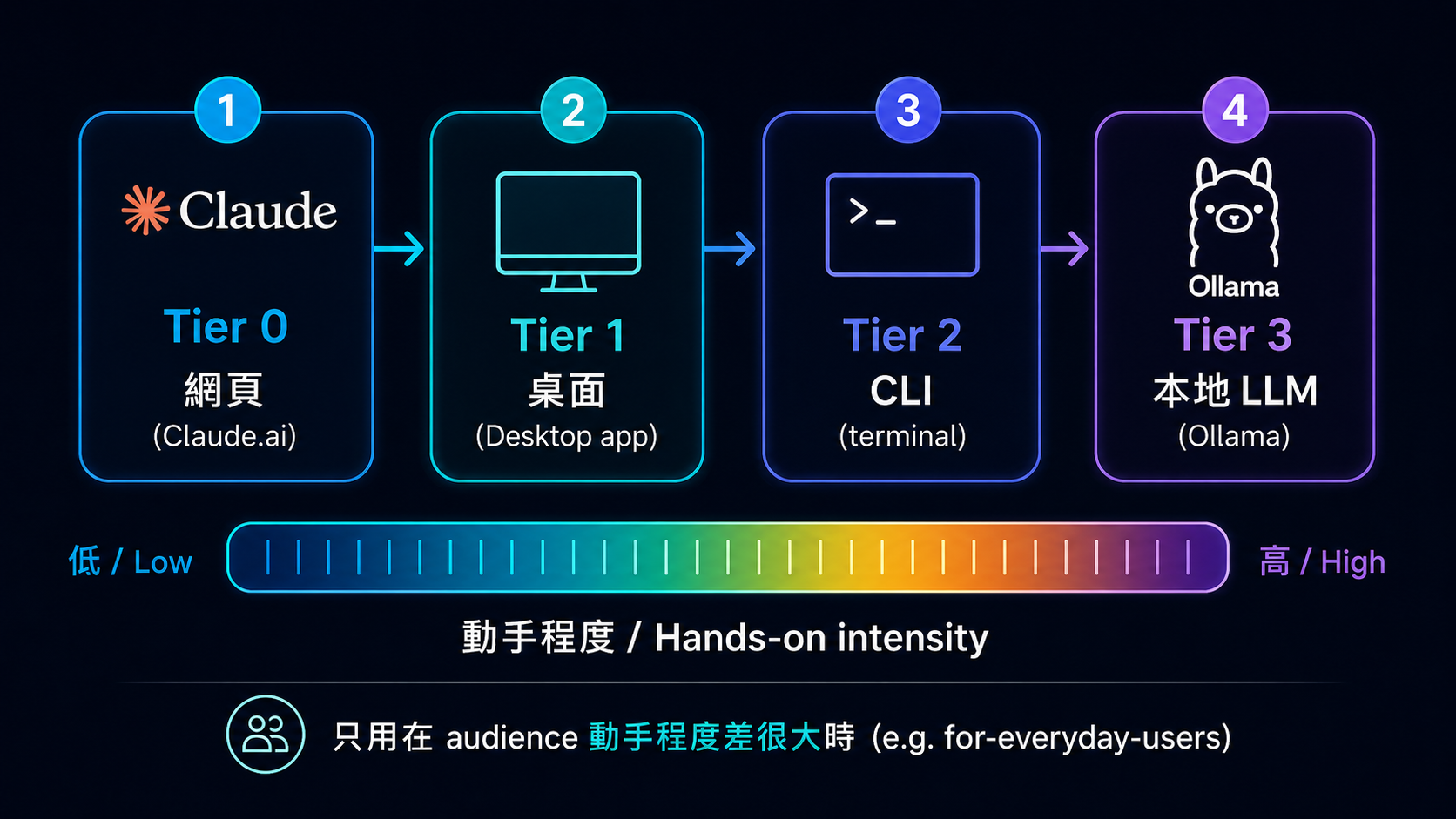 用 tier 的條件:audience 內部「動手程度差很多」。Everyday users 從「打開 Claude.ai」到「跑 Ollama 本地 LLM」差距太大,不分 tier 會混亂。
用 tier 的條件:audience 內部「動手程度差很多」。Everyday users 從「打開 Claude.ai」到「跑 Ollama 本地 LLM」差距太大,不分 tier 會混亂。
Flat 結構(其他 4 個 branch 都用這個)¶
單一個 list,照子主題分類(Coding Agents / Code Review / Workflow Tools 等)。 用 flat 的條件:audience 內部相對同質——研究者多半願意動手用 CLI、開發者一定會寫 code,沒必要分 tier。
什麼時候從 flat 升級成 tier¶
觀察 issue / PR 是否反覆出現「這個 entry 太進階 / 太簡單」抱怨。若 ≥3 個讀者反映該 branch 內 entry 落差太大,考慮分 tier。
自我引用排除原則¶
WenyuChiou/* repo 一律不收(已從 catalog 移除 32 instances)。
例外(什麼條件下作者自己的 repo 才能加回去)¶
- 該 repo 在某個 stage / branch 是唯一夠用的選項(沒其他社群替代)
- 至少 2 個 stage maintainer 簽字同意
- 在 entry notes 明確標註「作者維護的 repo,含利益關係」
- 加一個「替代品」連結,方便讀者比較
目前 0 個 entry 滿足這 4 條——保持 0 個是健康狀態。
加新 branch 的決策樹¶
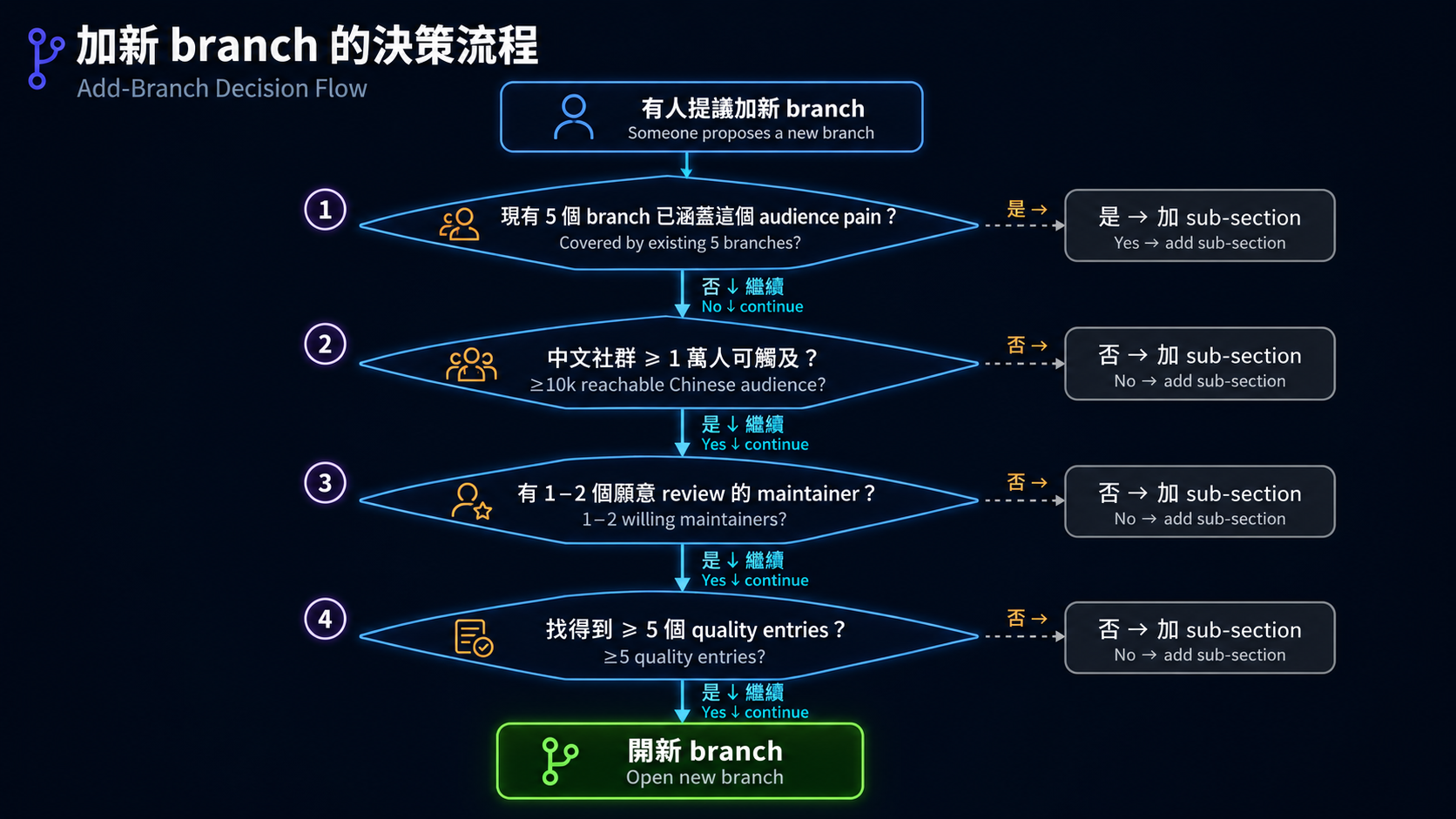
範例:要不要加 for-data-scientists?¶
- pain 已被 for-researcher 涵蓋(文獻 RAG、實驗設計)
- audience scale 大,但跟 researcher 重疊高
- 結論:不加 branch,但可以在 for-researcher 加「資料科學工具」 sub-section
範例:要不要加 for-product-managers?¶
- pain 已被 for-knowledge-worker 涵蓋(會議紀錄、report、跨 team 溝通)
- audience scale 大但邊界跟 knowledge-worker 模糊
- 結論:不加 branch,在 for-knowledge-worker 加「產品經理」use case
5 條 branch 的 maintenance 想法(不是 SLA)¶
社群 repo 的維護是「能做就做」、不是排程義務。下面是大致方向:
Review 頻率¶
- 沒有強制節奏。CI 已設定每月自動跑 link rot + star drift(被動的)。
- 有空想動的人 → 跑
python scripts/refresh-stars.py看哪些 entry 過時、python scripts/check-links.py --fast看哪些連結壞掉。
Entry 加入 / 移除節奏¶
- 加入:看到值得收的就 PR。不必為了「衝量」主動找。
- 移除:archived / 長期沒 commit / license 變奇怪 → 看到再標 ⚠️ 或 PR 拿掉。
跟 main path stages 的同步¶
- Stage 改了某個 entry,branch 引用該 entry 的地方順手更新就好——沒做也不會壞。
Maintainer 自薦 / 退場機制¶
- 想擔任 maintainer 開 issue 自薦就好,不用承諾什麼具體期間。「我 review 一次」也算貢獻。
- 退場:不需要 ceremony——維持沉默 2 個月,自動視為退場,新人接手
- 詳見
CONTRIBUTORS.md
不在這份的內容¶
- 個別 branch 的 entry 詳細:見
for-X.md本身 - stage 設計理由:見
../stages/DESIGN.md - entry schema / 用詞規範:見
../resources/style-guide.md