Stage 6 — 上下文管理(Context Engineering):RAG 與 Memory¶
⏱ 時間估算:2 週(約 10 小時)
💡 這 stage 用語密度高(RAG / 向量資料庫 / embedding / chunking / hybrid search / reranking⋯)→ 不熟先翻
resources/glossary.md3。📋 本章組成:定位 → 入口 → RAG 主軸(基礎 + 進階 + DSPy + Eval)→ Bridge → Memory 主軸(3 pattern + Trio + 進階)→ Chunking → Reflexion / Reasoning → 練習 → Projects
🔑 關鍵名詞:見
resources/glossary.md3(memory / RAG / embedding / chunking / reranking)
本 stage 的核心不是「多背一點名詞」,而是理解 agent 如何管理 context。
- RAG 解決的是:現在要從外部知識庫查哪些資料?
- Memory 解決的是:agent 應該跨對話、跨 session、跨任務記住什麼?
- Context Engineering 是更上層的問題:每次 LLM call 前,該把哪些資訊組進 prompt,讓模型在有限 context window 內做出正確決策?
→ 接著 Stage 7 三層工程分工:Prompt = 單次怎麼問 / Context = 這次該給哪些資訊 / Harness = 整個 agent system 怎麼跑起來。本 stage 是中間那層。
Agent 需要的兩種 context 能力¶
- Retrieval:從外部知識庫找出和當前任務相關的資料。
- Memory:保留跨對話、跨 session、跨任務的狀態、偏好與經驗。
RAG(Retrieval-Augmented Generation) 是目前最常見的 retrieval 架構;Memory 則負責讓 agent 記得使用者、任務歷史與自己的過去經驗。這一章會把兩者分開講,避免把「查資料」和「記事情」混在一起。
先把名詞切開:Retrieval / RAG / Vector Store / Memory 不是同一件事¶
| 名詞 | 不要混淆成 | 白話解釋 |
|---|---|---|
| Retrieval | RAG 全部 | 找資料的動作 |
| RAG | Vector DB | retrieve + generate 的整體流程 |
| Embedding | Memory | 把文字轉成向量、方便相似度搜尋 |
| Vector store | RAG | 儲存與搜尋 embedding 的地方 |
| Chunking | Retrieval 本身 | 把文件切成適合被搜尋的片段 |
| Memory | RAG | agent 對使用者、任務與過去經驗的持久管理 |
🎯 Context Engineering 是什麼(先定位)¶
一句話:Context Engineering = 決定每次呼叫 LLM 時、要把哪些資訊塞進它看得到的視窗(context window)。
重點不是「開了幾次對話」、是「每次對話裡塞了什麼」。Karpathy 2025-06 原 tweet 講得最精準:「把對下一步有用的資訊剛好填進視窗的精細藝術」。
📺 視覺學習:李宏毅 2025 第 2 講 — Context Engineering:AI Agent 背後的關鍵技術(NTU 生成式人工智慧與機器學習導論 2025)
三層 stack 中的位置¶

詳細對照表見 Stage 2 進階。
本 stage 處理 4 個 sub-problem 中的 2 個(Lance Martin 2025 framework)¶
| Sub-problem | 解決什麼 | 具體例子 | 本 stage cover? |
|---|---|---|---|
| Select | 要把哪些外部資訊撈進視窗 | user 問「我家附近哪間 cafe 好吃」→ 從 yelp DB 撈 3 家評分高的 → 塞進 prompt | ✅ 主軸(RAG / vector search / GraphRAG) |
| Write | 要把哪些互動 / 教訓寫進長期記憶 | user 上週說「我吃純素」→ 寫進 memory;這週又問餐廳推薦時、retrieve 出來避免推肉食 | ✅ 主軸(memory layers) |
| Compress | 對話太長怎麼壓 | 50 輪對話超過 200k token → 自動摘要前 40 輪、保留最後 10 輪原文 | ⚠️ 部分(這裡 + Stage 7 Harness context manager) |
| Isolate | 多 agent 各自視窗怎麼分 | supervisor 看全局、worker 只看自己那段、彼此不串擾 | ❌ Stage 7 multi-agent 處理 |
4 個常被搞混的概念 — 一張表分清楚¶
| 詞 | 是什麼(抽象 / 具體) | 範例工具 |
|---|---|---|
| Memory | agent 跨對話 / 跨 session 記事情的能力(抽象概念) | LangChain ConversationBufferMemory / mem0 / Letta |
| Embedding | 把文字轉成 N 維向量、讓相似度可計算(資料轉換) | sentence-transformers 跑出 768 維向量 / OpenAI ada-002 |
| Vector DB | 存 + 查 embedding 的儲存層(基礎設施) | Chroma / Qdrant / Weaviate / pgvector |
| RAG | 「retrieve 相關片段 → 塞進 prompt → 生成」這個 pattern(架構模式) | LlamaIndex / LangChain RAG chain |
→ 核心區分:Memory 是能力、Embedding 是資料轉換、Vector DB 是儲存、RAG 是架構 pattern——這 4 個常被混用、實際上是 4 個不同層的概念。
RAG vs Long Context vs Fine-tuning — 何時用什麼¶
LLM 知道你的私有 / 領域資料、有 3 種主要做法。本 stage 教 RAG,但你要知道何時不該用:
| 選擇 | 適合 | 不適合 | 成本 |
|---|---|---|---|
| RAG (外部 retrieve) |
大型 / 變動 / 私有知識庫、需要 citation 引用來源 | 推理需要全文一起看的任務、需要跨文件 multi-hop reasoning | 每 query 多 1 次 vector search 的 latency |
| Long Context (直接塞 prompt) |
< 200k token 的中型文件、一次性查詢、需要 cross-doc reasoning | 知識庫大 / 經常變動 / 想要 citation | 每 query 燒大量 input token(即使有 prompt caching) |
| Fine-tuning (改 model 權重) |
風格 / 格式統一、特定領域語言(醫療、法律、code) | 知識會變、要 citation、不想練 model | 訓練成本 + 維護成本 + 模型 lock-in |
→ 怎麼選:先試 RAG(成本最低、變動最容易)→ RAG 撈不到才考慮 Long Context → 兩個都不行才考慮 Fine-tuning。進 Stage 7 學 fine-tune deploy。
📌 學習目標¶
- 建一條基本 RAG 流水線(chunk → embed → store → retrieve → generate)
- 看出 RAG 不該用在哪些地方(以及該用在哪些地方)
- 區分 short-term、long-term、episodic、semantic memory
- 理解 vector embedding 與相似度搜尋
- 知道進階 RAG(GraphRAG / Contextual Retrieval / Hybrid Search)何時加、何時不加
🚪 進入條件¶
你應該已經:
- 完成 Stage 3(會寫 tool use、會呼叫 LLM API、看得懂 ReAct loop)—— 硬性技術前置
- 走過 Stage 4(agent frameworks)+ Stage 5(Claude Code 生態)—— curriculum 主線是 3 → 4 → 5 → 6(見 README 學習地圖);非硬性技術前置,但 RAG / memory 常跟 framework + Claude Code memory 機制搭配、照順序走過理解更完整,且 Stage 7 預期你已完成 4 + 5 + 6
- 能跑 Python pip install 安裝 SDK(後面練習會用到 chromadb、sentence-transformers 等)
- 對 list / dict / generator 等基礎 Python 結構上手
沒到的話 → 回 Stage 3 或 Stage 0 環境設定。
📚 必修閱讀¶
- LlamaIndex — RAG concepts — 最清楚的入門
- LangChain — RAG tutorial — 動手做
- Pinecone — Learning Center — vector DB 基礎
- Anthropic — Contextual Retrieval — Anthropic 搭配 prompt caching 的 RAG 寫法
- LangChain — Text splitters — chunking 策略入門
🙏 Memory 章節特別推薦
datawhalechina/hello-agents:本 stage 探討 memory 的概念跟初級實作、要 chapter-length 深入版請看 hello-agents 對應章節——short-term / long-term memory 的差異、context engineering 怎麼動態組裝、session 持久化、forgetting strategy 都講得最完整。本 stage 是路線圖、那邊是深度教材。
🧭 單元指引(漸進式 flow)¶
本章按 RAG 先學、Memory 後學 的順序走——RAG 是 context engineering 最基礎、最常用的工具,Memory 是 agent 跨對話/跨 session 的能力;先把 RAG pipeline 跑通、再帶到 Memory 設計,最後回頭看 Chunking 細節。
閱讀順序建議:
- 🌐 RAG 基礎流水線(下一節)— 建立 mental model
- 🚀 進階 RAG 技巧 — GraphRAG / Contextual Retrieval / Hybrid Search 等 production 升級
- 🌉 從 RAG 到 Memory — 為什麼 RAG 還不夠、需要 Memory 補哪段
- 🧠 Memory 設計 — 短期 vs 長期、3 種 pattern、CoALA framework
- 🧩 Chunking 細節 — RAG / Memory 都會用到的技術深入
讀這章時可以順便思考:RAG 不適合哪些應用場景?哪些場景適合 RAG,但基本 RAG 還不夠好?這會帶到後面的 GraphRAG / Self-RAG / RAPTOR 等進階技術。
🌐 RAG 基礎流水線¶
RAG(Retrieval-Augmented Generation)= 「retrieve 相關片段 → 塞進 prompt → 生成」這個 pattern。可以想成在幫 agent 蓋圖書館——你要先把書放好、分類好,後續要查資料時,才會又快又精準。
最基礎的 RAG 拆成兩條流水線:
- 資料預處理(ingest 一次):ingest → chunk → embed → store(index)。這一步是在建立可檢索的知識庫。
- 檢索生成(每次 query):retrieve → generate。這一步是在使用者提問時,找出相關內容,再交給 LLM 生成回答。
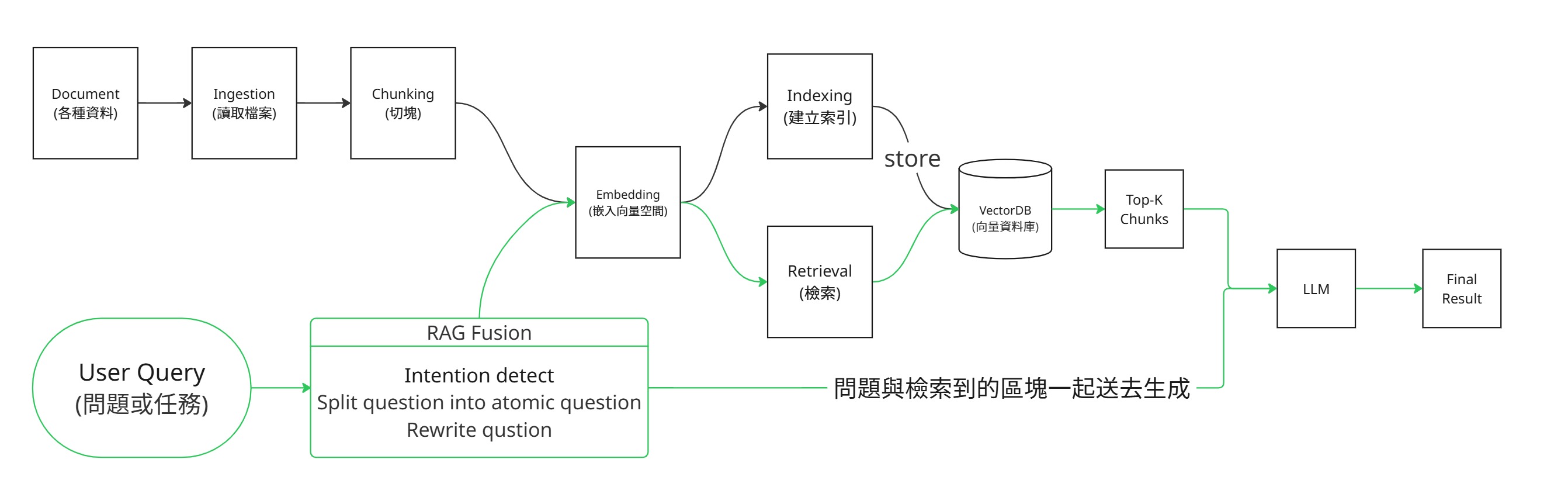
圖中的 RAG Fusion、query rewrite 等屬於進階檢索技巧。第一次學 RAG 時,先理解主線流程即可。
5 個 step 解讀:
| Step | 做什麼 | 在哪一條 pipeline | 技術細節在 |
|---|---|---|---|
| 1. ingest | 把資料載入(PDF / web / DB / 對話 log) | 預處理 | LlamaIndex / LangChain 各自 loader |
| 2. chunk | 把文件切成小塊(500-2000 token / chunk) | 預處理 | 見後段 🧩 Chunking 細節(先讀 RAG / Memory 主軸、技術深入留到那邊) |
| 3. embed | 每個 chunk 轉成 N 維 vector | 預處理 | sentence-transformers / OpenAI ada-002 |
| 4. store | vector + metadata 存進 vector DB | 預處理 | Chroma / Qdrant / pgvector |
| 5. retrieve + generate | query 也 embed → top-k semantic search → 拼進 prompt → LLM 生成 | 每次 query | 通用 LLM API |
上面只是最小骨架。最常踩的坑 3 個:
- chunk 太大 / 太小:太大、retrieve 撈到的 chunk 裡只有一句相關、其他都是雜訊;太小、失去前後文(見 Chunking 細節)
- embedding model 選錯:中文文件用英文 model、retrieval 精度直接掉一半
- top-k 設太大 / 太小:太小、漏 relevant chunk;太大、雜訊高 / token 燒
📚 想看更多 RAG 踩坑指南 + 解法:NirDiamant/RAG_Techniques ★ 大型 production RAG cookbook、含 30+ 技巧 + Jupyter notebook 範例。
📄 RAG 真正常掛的兩個地方,別只顧 chunking:(1) 解析(ingest)——PDF→乾淨 markdown 是 garbage-in 的源頭:docling-project/docling(★61k、MIT)、opendatalab/MinerU(中文 / 科學 PDF 強,AGPL 注意授權)、microsoft/markitdown(★150k+、MIT)。(2) 選嵌入模型——第一個檢索品質決策,別瞎挑:看 MTEB leaderboard,中文 / 多語常用 BGE-M3(★12k、MIT)。
跑完基本骨架後,跑 動手練習 1-4(embeddings / vector DB / chunking / 完整 pipeline)建立手感、再進下一節 進階 RAG 技巧。
🚀 進階 RAG 技巧(跑完基本 RAG 之後再看)¶
下面六個 subsection 是 2024-2026 production RAG 最常加上的槓桿,按「加進 pipeline 哪一層」分組: - Retrieve 後 —— GraphRAG / Contextual Retrieval / Hybrid Search & Reranking - Retrieve 前(query 改寫)—— Query Transformations - Retrieve 期間(control flow)—— Adaptive / Agentic RAG - Index 結構 —— RAPTOR - 2024-2026 縱覽 —— 其他 17 個值得知道的技巧
先跑完上面 RAG 基礎拿到基準版本、再回來看這裡——不然你會在沒有基準的情況下調參數,永遠不知道是哪個改動帶來提升。
| 技巧 | 解決什麼問題 | 加在 pipeline 哪一層 | 成本 |
|---|---|---|---|
| GraphRAG | vanilla RAG 不會做 multi-hop / 跨文件 entity-relation 推理 | retrieve 前(建 graph)+ retrieve 時(graph traversal) | 高(要先建 KG、需 LLM 抽 entity) |
| Contextual Retrieval | chunk 失去原文件 context、retrieval 撈錯片段 | chunk 後 / embed 前(加 contextual header) | 中(一次性、搭 prompt caching 後便宜 90%) |
| Hybrid Search & Reranking | 純 vector 漏字面命中、top-k 雜訊高 | retrieve 中(並查 BM25)+ retrieve 後(cross-encoder rerank) | 低(成熟工具直接接) |
🔗 GraphRAG — 知識圖譜 + RAG¶
Mental model:vanilla RAG 把文件切成 chunk、靠 embedding 相似度撈片段——但它不知道哪些 entity 是同一個東西、entity 之間有什麼關係。GraphRAG 在 ingest 階段先用 LLM 把文件抽成 (entity, relation, entity) 三元組建知識圖譜,retrieve 時除了向量比對、還做 graph traversal 撈到「相關 entity 的相關 entity」。
何時用: - 任務需要 multi-hop reasoning(A → B → C 才能回答) - 跨多份文件、entity 互相引用(公司財報、論文引用、調查報告、法律案例) - 問題形如「X 影響了什麼 Y、Y 又連到哪些 Z」——vanilla RAG 通常只撈到 X 那塊文件
何時不用: - 文件之間沒有 entity-relation 連結(純 FAQ、產品手冊各自獨立) - 知識庫小(< 1k chunk)——vanilla RAG 已經夠 - 預算緊——建 KG 的 token 成本可能是普通 RAG 的 10-50 倍
代表 framework: - HKUDS/LightRAG ★ 35.1k MIT EMNLP 2025 — 目前社群最熱的選擇、輕量、KG + vector hybrid、cost 比 Microsoft 版低 - Microsoft GraphRAG — 原版 reference 實作、Apache-2.0、含 community detection - gusye1234/nano-graphrag — < 1000 行的最小實作、適合先讀懂原理
Paper:From Local to Global: A Graph RAG Approach to Query-Focused Summarization (Edge et al. 2024) — Microsoft GraphRAG 的原始 paper、解釋 community summarization 為什麼能解 global query
🪶 Contextual Retrieval — Anthropic 的 prompt-caching 解法¶
Mental model:vanilla chunk 失去原文件 context——「Q3 revenue grew 15%」這個 chunk 抽出來、你不知道是哪家公司、哪一年的 Q3。Anthropic 2024 提出:ingest 時用 LLM 為每個 chunk 寫一段 50-100 token 的 contextual header(「This chunk is from ACME Corp 2024 Q3 earnings, discussing the cloud segment...」)拼到 chunk 前面再 embed。搭配 prompt caching 讓「整份文件 + 每個 chunk」這個 prompt 只計費一次、後面所有 chunk 共用 cache。
何時用: - chunk 字面意思跟原文件主題距離遠(財報、研究報告、長 narrative 文件) - 你願意一次性付 ingest 成本、換 retrieve 精度 - 已經在用 Claude / 想用 prompt caching(其他 model 也能跑、就是沒 cache 折扣)
何時不用: - chunk 本身就是 self-contained(FAQ、產品介紹頁、定義條目) - 知識庫經常變動(每改一次就要重 ingest) - 預算極緊——即便 cache 折扣後、ingest 成本仍比 vanilla 高
為什麼省 90% cost:Anthropic 報告 prompt caching 把「整份文件當 cached prefix」、每個 chunk 只送差異——比起每 chunk 都餵整份文件、成本降到約 1/10。但這只省 ingest、不省 retrieve 階段。
代表實作: - Anthropic — Contextual Retrieval blog ⭐ — 官方說明 + benchmark(failed retrieval rate 從 5.7% 降到 1.9%) - Anthropic cookbook — 端到端 Jupyter notebook、含 prompt 模板
搭配技巧:Anthropic 同篇 blog 還建議疊上 Contextual BM25(contextual chunk 同時餵 vector + BM25)+ reranking——剛好接到下面 Hybrid Search & Reranking。
🎯 Hybrid Search & Reranking — production RAG 的兩個常見強化元件¶
Mental model: - Hybrid Search = vector similarity(語意像)+ BM25 / keyword(字面像)並查、用 RRF (Reciprocal Rank Fusion) 之類融合分數。解決純 vector search「query 跟 chunk 同義但用詞不同沒撈到」+「人名 / 編號 / 罕用詞語意 embedding 太弱」的雙重盲點。 - Reranking = 第一階段 retrieve top-50(recall 優先、寬鬆撈)→ 用 cross-encoder reranker 重新打分排成 top-5(precision 優先、精準篩)。cross-encoder(query + chunk 一起進 model)比 bi-encoder(query / chunk 分開 embed)精準很多、但太慢、所以只用在第二階段。
為什麼是「必加的強化元件」:production RAG 評測幾乎一面倒——加 hybrid + reranker 後 recall@5 通常從 70% 上下提到 85-90%、邊際成本低、實作成熟。這是 cost / benefit 最好的兩個改動。
何時用: - production RAG(不是 demo / 練習) - query 包含人名、產品編號、技術術語、罕見字(純 vector 容易漏) - 預算允許每 query 多 100-300ms latency
何時可以暫緩: - 練習階段 / MVP(先把 vanilla RAG 跑通) - 預算極緊 / latency 極敏感(reranker 是額外一次 model call)
代表工具:
- Hybrid search:Weaviate(內建 BM25 + vector + RRF)/ Qdrant(支援 sparse + dense vector)/ pgvector + Postgres FTS
- Reranker:Cohere Rerank API(商業、最常用)/ BGE Reranker(開源、HuggingFace、中文表現好) / Jina Reranker
- Framework 內建:LlamaIndex 的 SentenceTransformerRerank / LangChain 的 ContextualCompressionRetriever
Paper / 入門: - Pinecone — Rerankers and Two-Stage Retrieval — reranker mental model 講最清楚 - Anthropic — Contextual Retrieval(上面已列)— 同時示範 hybrid + reranker、有 benchmark
Query Transformations — HyDE / Multi-Query / RAG Fusion¶
Mental model:vanilla RAG 把 user query 直接 embed 去查——但 query 跟文件用詞 / 風格 / 抽象層級經常差太多(user 問「我胃痛怎麼辦」、文件寫「上腹部疼痛之鑑別診斷」)。Query transformations 在 retrieve 前先改寫 query、讓改寫版本更接近文件形式。
3 個代表技巧:
| 技巧 | 怎麼改寫 | 何時用 |
|---|---|---|
| HyDE(Hypothetical Document Embeddings) | 先讓 LLM 對 query 生成「假想答案」、用答案 embedding 查 | query 跟 chunk 用詞風格差距大 |
| Multi-Query | LLM 把 query 改寫成 N 個變體分別 retrieve、union 去重 | query 太短 / 模糊 / 多義 |
| RAG Fusion | Multi-Query + RRF 融合 N 個 retrieval 結果 | 同上、想要更穩定的排名 |
何時不用:query 已經是長 + 結構化(RAG over code、user 直接 paste error stack trace)——改寫反而引入雜訊。
Paper / 實作:
- HyDE (Gao et al. 2022) — 原始 paper
- RAG Fusion (Raudaschl 2023) — Multi-Query + RRF 的 reference 實作
- LangChain 內建 MultiQueryRetriever / LlamaIndex HyDEQueryTransform
🔁 Adaptive / Agentic RAG — Self-RAG / CRAG / Adaptive RAG(讓 retrieval 變成可判斷的流程)¶
Mental model:上面所有 RAG 技巧都假設「query 來 → retrieve → generate」是固定 pipeline。Self-improving RAG 把這個 pipeline 變成有判斷能力的 agent loop——LLM 自己決定要不要 retrieve、判斷 retrieve 品質、不夠就再查或改 query。這是 2024 RAG 研究的主軸。
| 技巧 | 怎麼自我修正 | Paper |
|---|---|---|
| Self-RAG | 訓練 LLM 輸出 [Retrieve] token 決定要不要查、retrieve 後輸出 [IsRel]/[IsSup]/[IsUse] 評分每個片段 |
Asai et al. ICLR 2024 |
| CRAG(Corrective RAG) | retrieval evaluator 打分;高信心直接用、低信心 fallback 到 web search、中信心做 query 改寫 | Yan et al. 2024 |
| Adaptive RAG | classifier 先判 query 複雜度、routing 到「不 retrieve / single-step / multi-step」三種策略 | Jeong et al. NAACL 2024 |
為什麼這是 2024 主軸:固定 pipeline 在簡單 query(「Tokyo 首都?」不用 retrieve)+ 複雜 query(multi-hop、cross-doc)兩個極端都吃虧。讓 LLM 自己 routing → 兩個極端都解。
何時用:production RAG、query 類型分布廣(從事實題到推理題都有)、願意付 1.5-3 倍 latency 換準確度。 何時不用:query 類型單一 / 預算 / latency 極緊。
實作:LangGraph 有官方 Self-RAG cookbook + CRAG cookbook + Adaptive RAG cookbook、可直接套。
🌳 RAPTOR — 階層式遞迴 retrieval(ICLR 2024)¶
Mental model:vanilla chunking 把文件切扁平 chunk——但整本書的主旨不在任何單一 chunk 裡。RAPTOR 把 chunk 遞迴聚類 + 摘要、建一棵多層樹:底層 = 原 chunk、中層 = 一群相關 chunk 的摘要、頂層 = 全文摘要。retrieve 時可選整棵樹搜尋、或選特定抽象層。
為什麼有用: - 抽象 query 撈得到(「這篇 paper 主要結論?」原 chunk 都沒這句、但頂層摘要有) - 細節 query 也撈得到(底層 chunk 保留) - 跟 GraphRAG 不同——RAPTOR 是樹(hierarchical summarization)、GraphRAG 是圖(entity-relation)
何時用:長文件(書、論文、報告)需要不同抽象層 query、知識庫 narrative 連貫。 何時不用:chunk 之間獨立(FAQ)、知識庫經常變動(重建樹貴)。
Paper / 實作:
- RAPTOR (Sarthi et al. ICLR 2024) ⭐ — 原始 paper
- parthsarthi03/raptor — 官方 reference 實作
- LlamaIndex 內建 RAPTOR pack
🧬 DSPy — 不寫 prompt、用 program 自動 optimize(Path 3 paradigm)¶
Mental model:傳統 RAG / Agent = 手寫 prompt + 手刻 chain。DSPy = 不寫 prompt——你只定義「signature」(input → output 的型別)、再寫 program(chain 結構);DSPy 自己用 LLM compile 出最佳 prompt + few-shot examples + retriever 設定。Stanford NLP group 2024 提出、Karpathy 推、目前 production 越用越多。
何時用: - 你的 RAG 用了 6 個月、prompt 累積到難維護、想自動 optimize - 同一 program 要切換不同 LLM provider(DSPy 自動 recompile) - agent system 有多個 step、想跟蹤 trace / metrics
何時不用: - 你只有一個 prompt、不需要 optimization - 第一次學 LLM、還沒摸過 prompting
代表 repo:stanfordnlp/dspy ★ 34.4k MIT、Stanford NLP group 官方、active 維護中。
怎麼放進 RAG:DSPy 跟本 stage 講的 RAG 技巧不衝突——你可以把 GraphRAG / Hybrid Search / Reranking 都當成 DSPy 的 module 來組、然後 compile。是 RAG 構築方式的「上層」typing 系統。
→ 跟 Path 1 / Path 2 reasoning 並列:Path 1 是「人手寫 prompt」、Path 2 是「訓練進 model 權重」、DSPy 是 Path 3「program 自動 search 出 prompt」。Stage 7 multi-agent 進階場景特別好用。
📊 RAG 進階技巧縱覽 — 2025-2026 三條主軸¶
進階 RAG 的 2025-2026 演化集中在 3 條主軸:
- 🧠 KG + Memory 融合 — 從 flat vector store 走向「結構化、可演化、可聯想」的知識表示。代表:HippoRAG 2(海馬迴啟發、KG + PageRank、跨文件 multi-hop)、A-MEM、KAG。
- 🎬 Multimodal RAG — 從文字 retrieval 走向圖像 / 影片 / 表格 native。代表:ColPali(PDF 頁面圖像直接 embed、繞過 OCR)、TV-RAG、MegaRAG。
- 🤖 Agentic RAG — retrieval 從固定 pipeline 變 agent loop 內的 tool(agent 自己決定查幾次 / 怎麼查)。代表:A-RAG、Self-RAG(已上面 Self-improving)、SoK: Agentic RAG survey 2026。
另外 2 個值得追的方向: - 🛡 RAG 安全 — corpus poisoning / prompt injection 進入 production 考量。代表:RAGPart / RAGMask。 - 🔧 不再手寫 prompt — 系統自動 search 出最佳 prompt + retriever 組合。代表:DSPy(Stanford「programming not prompting」典範、見上方 DSPy 段落)。
5 個值得深挖的代表作(速查):
| 技巧 | 一句話 | 連結 |
|---|---|---|
| HippoRAG 2 | KG + Personalized PageRank、跨文件 multi-hop、海馬迴啟發 | Gutiérrez et al. ICML 2025、OSU-NLP-Group/HippoRAG ⭐ |
| ColPali | PDF 圖像直接 embed、繞過 OCR、multimodal RAG 入門 | Faysse et al. 2024 |
| A-RAG / SoK Agentic RAG | retrieval 當 tool、agent 自己決策查幾次 | Ayanami0730/arag、SoK survey ⭐ |
| DSPy | 不寫 prompt、用 program + signature、auto-optimize | stanfordnlp/dspy ★ 34.4k |
| LightRAG | MS GraphRAG 的 lightweight 替代、EMNLP 2025 | HKUDS/LightRAG ★ 35.1k(已在 GraphRAG 段落) |
📚 完整縱覽 — 其他 12 個值得知道的進階 RAG 技巧(展開看)
| 技巧 | 一句話 | 年份 / Paper | |---|---|---| | **Sentence-Window Retrieval** | embed 句子、retrieve 後回傳 ± N 句 window | LlamaIndex 內建 | | **Parent-Child / Small-to-Big** | embed 小 chunk、回傳 parent chunk | LangChain `ParentDocumentRetriever` | | **Multi-Vector Retrieval** | 一個 chunk 多個 embedding(摘要 / 原文 / 假想問題)| LangChain `MultiVectorRetriever` | | **ColBERT / 後互動 retrieval** | token-level 比對而非 pooled embedding | [Khattab & Zaharia 2020](https://arxiv.org/abs/2004.12832)、[RAGatouille](https://github.com/AnswerDotAI/RAGatouille) | | **LongRAG** | 大 chunk(4k)+ long-context reader、減少 retrieval 次數 | [Jiang et al. 2024](https://arxiv.org/abs/2406.15319) | | **MemoRAG** | memory model 把 KB 壓成 latent memory、retrieve 用線索觸發 | [Qian et al. 2024](https://arxiv.org/abs/2409.05591) | | **KAG**(Knowledge-Augmented Generation)| 嚴格 schema KG + 邏輯推理、金融 / 醫療 / 法律場景 | [Liang et al. 2024 (Ant Group)](https://arxiv.org/abs/2409.13731) | | **MiA-RAG**(Mindscape-Aware)| 先建文件高層摘要 mindscape、用它引導 retrieval 跟回答 | [arXiv:2512.17220](https://arxiv.org/abs/2512.17220) ⭐ 2025-12 | | **QuCo-RAG**(Quality-Controlled)| 用 pretraining 統計判斷該不該 retrieve、罕見 entity 觸發查、減 hallucination | [arXiv:2512.19134](https://arxiv.org/abs/2512.19134) ⭐ 2025-12 | | **MegaRAG** | 多模態 KG、長文件抽 entity + relation + 視覺、建層級圖 | [arXiv:2512.20626](https://arxiv.org/abs/2512.20626) ⭐ 2025-12 | | **TV-RAG** | training-free 時間感知 RAG、長影片 + 字幕 + 視覺對齊 | [arXiv:2512.23483](https://arxiv.org/abs/2512.23483) ⭐ 2025-12 | | **RAGPart / RAGMask** | 對 RAG corpus poisoning 攻擊的輕量防禦 | [arXiv:2512.24268](https://arxiv.org/abs/2512.24268) ⭐ 2025-12 |🌉 從 RAG 到 Memory — 為什麼 RAG 還不夠¶
讀到這你已會跑基本 RAG + 知道幾個 production 槓桿。但回頭看 Context Engineering 列的 3 個 problem domain——你只解決了 Retrieval,Memory 管理還沒碰。為什麼這兩件事要分開?
RAG 解決「從外部知識庫 retrieve 相關片段」——但 agent 還需要「自己 跨對話 / 跨 session 記事情」。這兩件事不是同一個問題:
| 維度 | RAG | Memory |
|---|---|---|
| 內容來源 | 外部(PDF / 文件 / web / DB) | agent 自己的對話 / 經驗 |
| 寫入時機 | ingest 一次性、後續每次 retrieve | 每輪對話、每次 task 都可能寫 |
| 內容性質 | 偏靜態事實、文件知識 | 偏動態:user preference、過去互動、累積教訓 |
| 取代得了 RAG 嗎? | — | 取代不了——你不會把每份 PDF 當「memory」 |
| 被 RAG 取代嗎? | — | 不會——RAG 不會「記住上次 user 說了什麼」 |
3 個 RAG 不夠用的場景(剛好對應到 Memory):
- 跨 session 記 user preference / persona——user 上禮拜跟 agent 說「我是純素」、這禮拜回來、agent 還記得不能推薦肉食。RAG 知識庫不會這樣自動更新。
- agent 過去成敗教訓累積(Reflexion 主場)——agent 第一次跑 task 失敗、反思「為什麼失敗」存起來、下次遇類似 task retrieve 進 prompt 避免重蹈覆轍。RAG 知識庫不會「記住自己的失敗」。
- Long-horizon task 中間狀態——agent 跑 100 step task、中間需要保留 working memory 不丟失。RAG 不適合做這種「短期 + 結構化 + 高頻寫入」的 state。
→ 結論:RAG 跟 Memory 是互補而非取代。Production agent 通常兩個都要:RAG 接外部知識、Memory 記自己跟 user 的互動。下節 Memory 設計 教你怎麼挑 memory pattern。
🧠 Memory 是什麼 + 怎麼設計¶
📺 視覺學習:李宏毅 2025 第二講 — 一堂課搞懂 AI Agent 的原理(含 read / write / reflection memory module)(NTU 生成式AI時代下的機器學習 2025)
Working memory vs Long-term memory — 兩種時間尺度¶
| 比較面向 | Working memory / 短期上下文 | Long-term memory / 持久記憶 |
|---|---|---|
| 中文可稱 | 工作記憶 / 短期上下文 | 長期記憶 / 持久記憶 |
| 核心意思 | 這次任務或這段對話中,模型當下看得到的資訊 | 存在外部,之後可跨 session 取回的資訊 |
| 持續時間 | 短,通常限於目前 session | 長,可跨 session |
| 技術基礎 | 上下文視窗(context window)/ prompt | 記憶儲存層(memory store)/ 使用者檔案 / 向量資料庫 |
| 適合記什麼 | 任務細節、剛剛說過的內容 | 穩定偏好、長期目標、背景資料 |
| 是否受 context 長度限制 | 會,因為模型一次能看的內容有限 | 較不會,因為可以先存在外部,需要時再取一小段放回來 |
| 生活例子 | 剛剛收到的手機驗證碼、正在進行對話的上一句話 | 你深化學會的知識、圖書館、知識庫、讀過的書 |
→ 在 agent 裡,「短期記憶」嚴格說更接近 working memory——它不是外部儲存、是目前 prompt / context window 裡看得到的內容。
Episodic / Semantic / Procedural memory — 三種內容類型¶
注意:上面 working / long-term 是時間軸,下面三種是內容軸——兩組分類正交、不互斥。Long-term memory 裡可以同時有 episodic + semantic + procedural 三種。
| 類型 | 中文 | 核心意思 |
|---|---|---|
| Episodic memory | 情節記憶 / 經驗記憶 | 過去某次任務、某次互動、某次失敗的具體經驗 |
| Semantic memory | 語意記憶 / 事實記憶 | 穩定知識、使用者偏好、背景事實 |
| Procedural memory | 技能型記憶(procedural memory) | agent 知道「怎麼做事」的規則、工具、workflow、skills |
→ 這 3 種對應 CoALA framework、production agent 通常 3 種都用得到。Reflexion 是典型的 episodic memory 應用(累積 trial 的成敗經驗)。
這裡的工作階段(session)可以理解成一次連續互動,例如同一段聊天、同一次任務,或同一次 agent 執行。
3 種設計 pattern(什麼時候用什麼)⭐ Track B 必看¶
不是所有 agent 都需要外部 memory store。Memory 架構選錯會花十倍 token 達同樣效果。
這是進練習前要建立的 mental model——下面練習 1-5 跑的是「pattern 3 vector store」,但 production 你可能不需要這麼複雜。
| Pattern | 適合場景 | 怎麼跑 | 成本 |
|---|---|---|---|
| 1. Naive buffer (全塞 context) |
短對話、≤ 10 turn、agent 不需要記跨 session 的東西 | 整段 history 每次都送進 prompt | 線性增長、token 燒得快 |
| 2. Summary + recent (摘要遠的 + 保留近 N 輪) |
中長對話、~ 50 turn、想壓縮但別丟太多 | 每 N 輪叫 LLM 把舊 history 摘成 1 段;prompt = summary + last N turns |
中等、有 LLM 摘要成本 |
| 3. Vector store + retrieval (外部 store + 每次 semantic search) |
跨 session、知識庫場景、agent 要「想起」久遠的事 | embed 過去 message → 存 vector DB → 每回合 query 相關片段拼進 prompt | 高(向量計算 + 儲存),但 token 用量穩定 |
怎麼選:
- 對話 chatbot 沒跨 session → pattern 1
- agent + 長對話、要記今天聊過什麼 → pattern 2
- agent + 跨 session + 知識庫(本 stage 練習場景)→ pattern 3
- production 大型 agent → 通常混用:近期 pattern 1/2、長期 pattern 3
💡 Track B 重點:你 Stage 7 寫 multi-agent 時,每個 agent 都會有「自己的 memory」+「shared memory」雙層——需要的 pattern 通常是 2 + 3 混用。先在本 stage 把 3 種 pattern 跑透,到 Stage 7 才不會被 multi-agent memory 設計卡住。
⭐ 5 個可上線使用的 Memory Layer(按 use case 挑)¶
Star 數與 benchmark 會變動;這裡重點不是排行,而是理解每個 memory layer 的設計取向。
學完 3 pattern 後、production 不必自己刻 memory store。下面 5 個都是 Apache-2.0 / MIT、active 維護、各擅其場:
| Framework | Stars | License | 主場 use case | 特色 |
|---|---|---|---|---|
| agentmemory | 7.7k★ | Apache-2.0 | Coding agent 跨 session 記憶 | MCP-universal(Claude Code / Cursor / Gemini CLI / Codex / Hermes / OpenClaw 都接得上)、95.2% R@5、92% token saving、51 MCP tools + 12 auto hooks、benchmarks-driven |
| mem0 | 55.6k★ | Apache-2.0 | Chatbot / 個人助理 user-level memory | Auto fact extraction + forgetting + namespace、production-tested、最大社群 |
| Letta(前身 MemGPT) | 22.7k★ | Apache-2.0 | 長 session agent(月為單位) | OS-style paging memory(working + archival 雙層)、persona stability、MemGPT paper origin |
| Zep | 4.6k★ | Apache-2.0 | Temporal KG-based memory | 把對話歷史建成 temporal KG、entity 之間有時間軸、適合需要 audit trail / time-aware reasoning 的 agent |
| graphiti | 27.5k★ | Apache-2.0 | 即時知識圖譜 agent 記憶 | 把 agent 過去的互動變成有時間軸的 knowledge graph、方便回頭查找;Zep 背後的引擎、可單獨使用 |
| LangMem | 1.4k★ | MIT | LangChain-native memory | LangChain 官方 memory lib、與 LangGraph 直接整合、適合已 commit LangChain stack |
怎麼挑: - 寫 coding agent → agentmemory(MCP-native、跟 Stage 5 ecosystem 完美 align) - 做 chatbot / 個人助理 → mem0(最成熟、最大社群) - 做 long-running 跨月 agent → Letta(OS-paging 強項) - 需要時間軸 + audit → Zep(temporal KG) - 已在 LangChain stack → LangMem(不必跳 framework)
另加官方 docs:Anthropic Memory Tool(Claude 官方 tool-based memory、file-based、API 直接 call)、LangChain Memory concepts(framework 內各 memory class 對比)。
進階:CoALA framework — agent memory 的 4 層 taxonomy¶
Sumers et al. 2023 — Cognitive Architectures for Language Agents 把 agent memory 拆成 4 種、是現在最常用的 mental model:
| 類型 | 存什麼 | 對應例子 |
|---|---|---|
| Working memory | 當前 task 上下文 | LLM context window 本身 |
| Episodic memory | 過去 task 的具體經驗 | Reflexion 反思記錄、past trajectories |
| Semantic memory | 抽象事實 / 知識 | RAG 知識庫、user profile、preference |
| Procedural memory | 怎麼做事的程式 / skill | tool definitions、Skills(Stage 5.3) |
→ 為什麼有用:上面 3 種 pattern(buffer / summary / vector)都只在處理 working + episodic。Production agent 4 層都要設計——CoALA 是檢查表,看看你的 agent 哪一層缺了。
進階:Generative Agents — 三分數打分(經典案例)¶
Park et al. 2023 — Generative Agents: Smallville 的小鎮模擬有 25 個 NPC agent、每個都有自己的 memory stream。retrieve 時用三個分數加權:
- Importance:LLM 自己幫每個 memory 打 1-10 重要性分(吃飯 = 2 分、分手 = 9 分)
- Recency:時間衰減(exponential decay)
- Relevance:跟當前 query 的 embedding 相似度
最終分 = α·importance + β·recency + γ·relevance、排前 k retrieve。這是 2024-2025 可上線使用的 memory layer(mem0 / Letta)的概念骨架。
💻 官方 code:joonspk-research/generative_agents ★ paper 配套的小鎮模擬 code repo、想跟著實作 memory stream + 三分數 retrieval 看這裡。
2024-2026 最新 Memory 作品 — 三條主軸¶
Memory research 2024-2026 集中在 3 條主軸:
- 🧠 結構化、可演化、可聯想 — 從 flat vector store 走向人腦 / Zettelkasten 啟發的記憶結構。代表:A-MEM(memory 之間自動建 link)、HippoRAG 2(KG + PageRank、海馬迴啟發)。
- 📚 2026 survey 大爆發 — 一年內 5 個重磅 survey + 跨領域整理。代表:Memory in the Age of AI Agents(3 維 taxonomy + benchmark)、Memory for Autonomous LLM Agents(write-manage-read loop 形式化)。
- 🛡 Memory security 變獨立子領域 — agent 跑久了、memory 會被 cross-session poisoning / 未授權存取攻擊。代表:Memory Security survey(Stage 7 安全 會接到)。
4 個值得深挖的代表作:
| 作品 | 一句話 | 連結 |
|---|---|---|
| Anthropic Memory Tool | Claude 官方 tool-based memory、API 直接 call、file-based | Anthropic Docs |
| A-MEM(Agentic Memory) | Zettelkasten-inspired、memory 之間自動建 link、會演化 | Xu et al. 2025 ⭐ |
| HippoRAG 2 | KG + Personalized PageRank、跨文件 multi-hop、ICML 2025 | Gutiérrez et al. 2025、OSU-NLP-Group/HippoRAG ⭐ |
| Memory in the Age of AI Agents(survey) | 3 維 taxonomy(temporal / substrate / control)+ benchmark 彙整 | Hu et al. 2025-12 ⭐ |
→ 跑很久的 agent(週 / 月為單位)、上面 survey 必讀。
📚 完整縱覽 — 其他 8 個值得知道的 memory 作品(展開看)
| 技巧 | 一句話 | 年份 / Paper | |---|---|---| | **MemGPT → Letta GA** | OS-paging memory、working / archival 雙層、long session 強項 | [Packer et al. 2023](https://arxiv.org/abs/2310.08560) → Letta GA | | **MemoryBank** | Ebbinghaus 遺忘曲線、被存取的 memory 強化、沒用的衰減 | [Zhong et al. 2023](https://arxiv.org/abs/2305.10250) | | **MemoryLLM** | self-updatable memory parameters 內建在 model(在權重而非 context)| [Wang et al. 2024](https://arxiv.org/abs/2402.04624) | | **mem0**(見 Production Memory Trio)| 可上線使用的 memory layer、auto fact extraction + forgetting | [mem0ai/mem0](https://github.com/mem0ai/mem0) | | **Memory for Autonomous LLM Agents**(survey)| write-manage-read loop 形式化、跨 2022-2026 整理 | [arXiv:2603.07670](https://arxiv.org/abs/2603.07670) ⭐ 2026 | | **From Storage to Experience**(survey)| 演化框架:Storage → Reflection → Experience 三階段 | [arXiv:2605.06716](https://arxiv.org/abs/2605.06716) ⭐ 2026 | | **ScrapMem** | bio-inspired on-device memory、"Optical Forgetting" 把老 memory 解析度漸降 | [arXiv:2605.03804](https://arxiv.org/abs/2605.03804) ⭐ 2026-05 | | **Memory Security survey** | long-term memory 被 cross-session poisoning / 未授權存取 / 組織內傳播風險 | [arXiv:2604.16548](https://arxiv.org/abs/2604.16548) ⭐ 2026 |🧩 Chunking 細節(技術深入)¶
好的 chunking 可以讓 LLM 在有限 context 內,用更精確、完整的資訊生成回答。它不是把文字平均切開。
切法取決於應用場景與文件內容。它會決定 retriever 看見的最小語意單位。
一個好 chunk 要同時做到兩件事:夠完整,讓模型看得懂上下文;夠聚焦,讓檢索不帶太多雜訊。chunk 太小會失去前後文,chunk 太大會讓相似度搜尋變鈍。
常見策略:
- 固定長度(Fixed-Length):照字元數或 token 數切。優點是簡單穩定;缺點是一板一眼,容易切斷段落、句子或表格。
- 滑動視窗(Sliding Window):每個 chunk 之間保留重疊區塊(overlap)。優點是比較不會在邊界掉資訊;缺點是索引量會變大。
- 遞迴切割(Recursive):先嘗試保留段落,如果長度還是不適合,再退到句子、字詞等更小單位。通常是入門 RAG 的好基準。
- 語意切割(Semantic Chunking):依 embedding 或語意變化切,也就是當前區塊與前一個區塊的語意相似度出現差異。適合長文件,但成本與複雜度較高。
- 混合策略(Hybrid):依照應用場景,思考不同文件結構該怎麼混搭切法。例如,一篇論文可能要保留章節、表格、公式與引用脈絡。
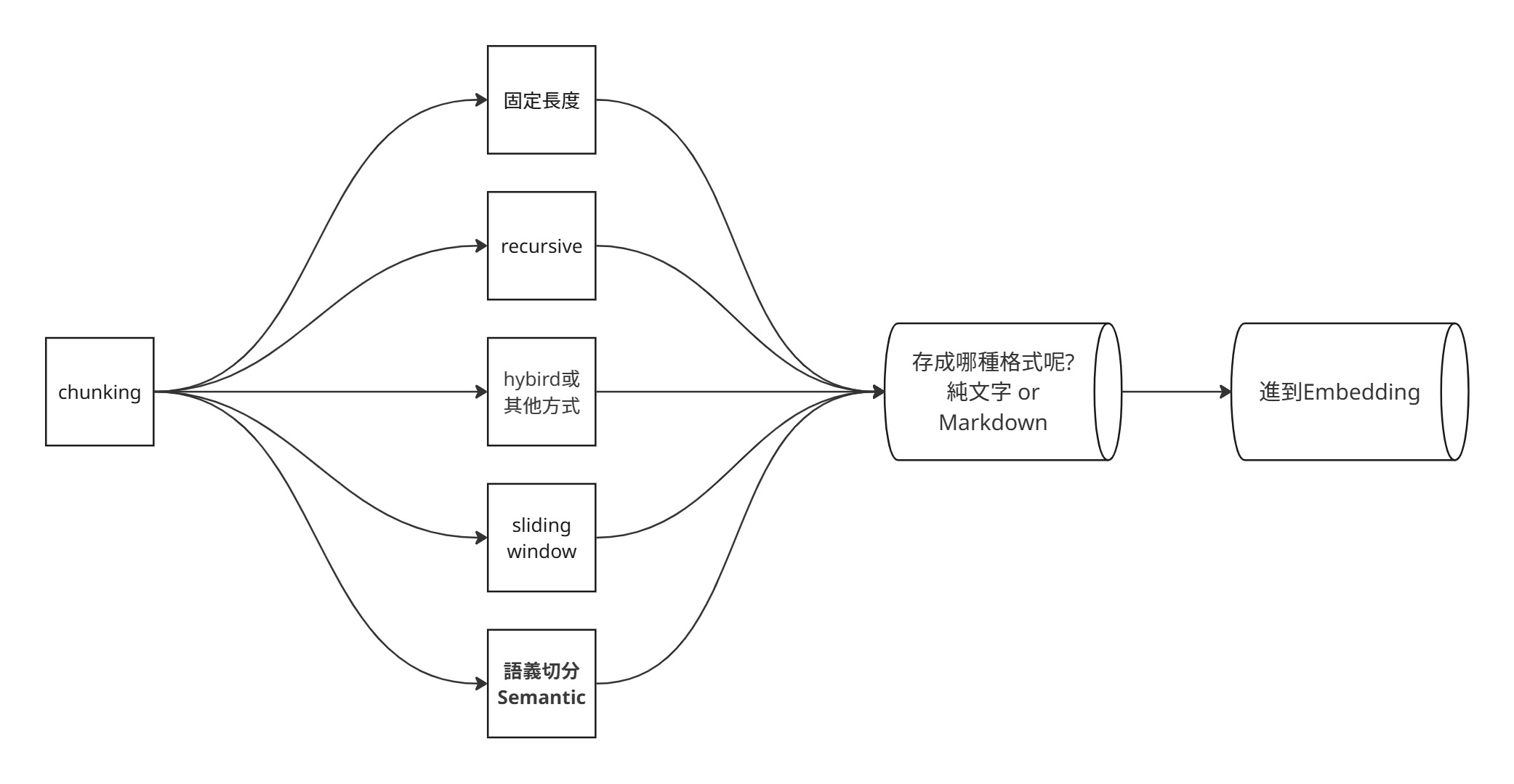
📚 經典教學:Greg Kamradt — 5 Levels of Text Splitting ★ chunking 入門必看、從 character-based 一路講到 agentic chunking 五個層次、含 Jupyter notebook。
第一次做 RAG 時,不要一開始就追求複雜切法。LangChain 文件建議多數情境先從 RecursiveCharacterTextSplitter 開始。
先跑出基準版本,再用後續 retrieval 結果決定要不要換策略。
from langchain_text_splitters import RecursiveCharacterTextSplitter
text = "這是一個很長的文件內容...(此處省略一千字)..."
splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
length_function=len,
)
chunks = splitter.split_text(text)
print(f"共切成 {len(chunks)} 個 chunk")
print(chunks[0])
直覺判斷 chunking 好不好,可以先看兩件事:
- 回答缺漏資訊,或有頭無尾:通常是 chunk 太小,或 overlap 不夠。
- 回答包含正確資訊,但混入無關內容:通常是 chunk 太大,或 top-k 撈太多。
進階思考:
- chunking 不是一次設定好就結束,要配合真實 query 與失敗案例反覆調整。
- chunk size、overlap、top-k、reranker 會互相影響,不要只單看其中一個參數。
- 想想看,如果今天要 RAG 的資料有含圖片的 PDF、會議字幕檔,要如何切割比較好?
- chunking 的進階變形(Sentence-Window / Parent-Child / Multi-Vector)見 進階 RAG 技巧縱覽表。
🪞 進階:帶持久記憶的 Reflexion 完整版 ⭐ Track B 選讀¶
本節是 concept + routing、不是練習。延續 Stage 3 反思 的基本版(single-session Actor / Critic loop),講為什麼有些反思需要持久記憶——這版本才真正屬於 Stage 6 主題。
Reflexion 完整版跟 Self-Refine 差在哪:
| 版本 | 跨輪保留什麼 | 跨 session 保留什麼 | 需要 memory pattern |
|---|---|---|---|
| Self-Refine(Madaan 2023) | 上一輪的 answer + critic feedback | ❌ 不保留 | 不需(pattern 1 buffer 即可) |
| 完整 Reflexion(Shinn 2023) | 同上 | ✅ 把過去 trial 的「反思摘要」存進 episodic memory,下次遇到類似 task 時 retrieve 進 prompt 當教訓 | 需要(pattern 3 vector store 或 pattern 2 summary) |
為什麼這個版本要 memory:Reflexion paper 的 verbal reinforcement learning 是「agent 跨 trial 累積教訓」——agent 嘗試 task → 失敗 → 反思「為什麼失敗」存起來 → 下次遇到類似 task 時把過去反思 retrieve 進 prompt,避免重蹈覆轍。這就需要 persistent episodic memory,跟本 stage 上面講的 3 種 memory pattern 直接接上。
典型架構(持久記憶完整版):
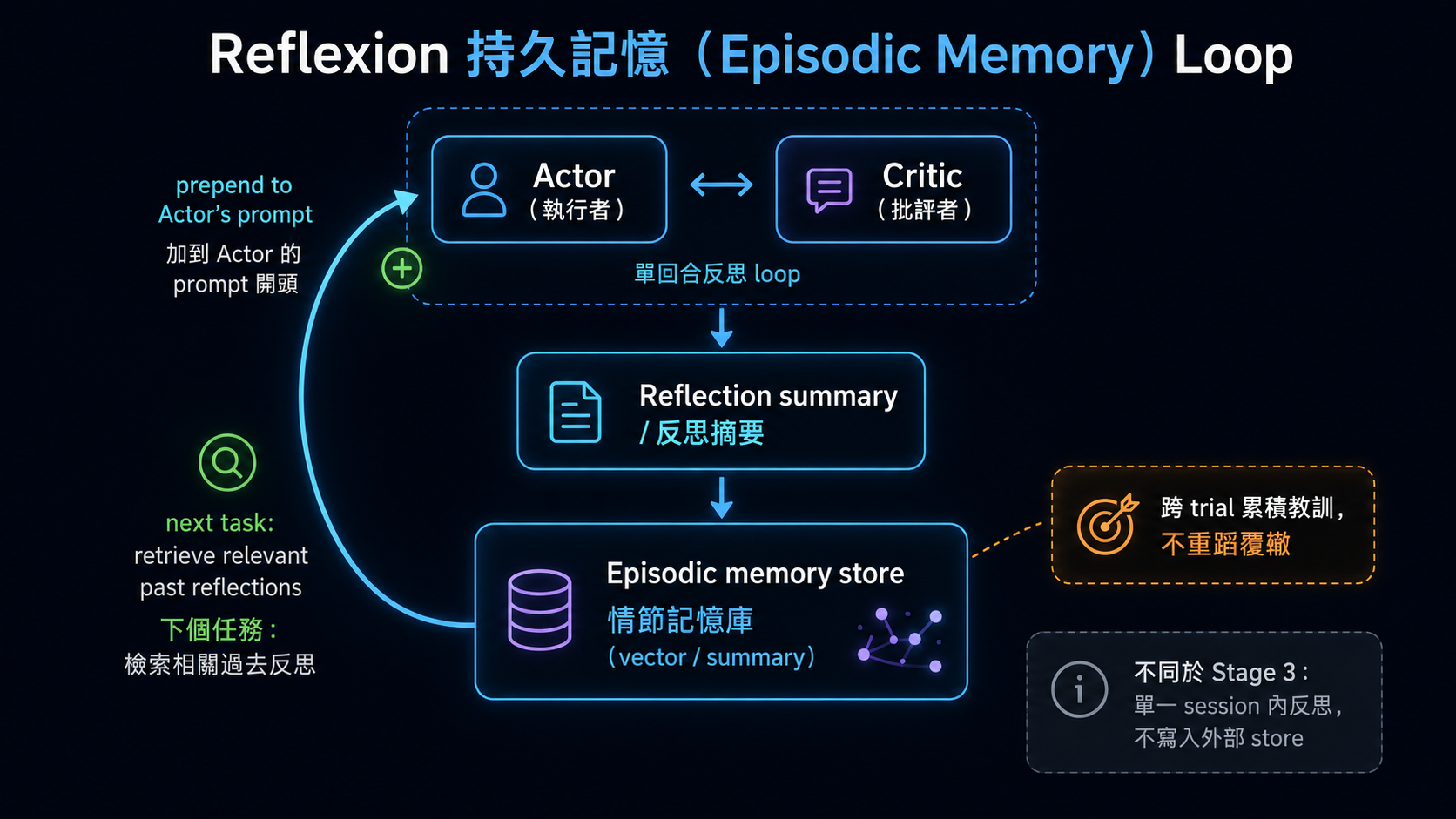
→ 跟 Stage 3 反思的差別:Stage 3 是 single-session in-context loop(沒外部 store)、本節是 persistent episodic memory store + retrieve(跨 trial 累積)。
📚 想動手 / 想深入¶
Paper: - Reflexion (Shinn et al. 2023) ⭐ — 完整版 paper,Algorithm 1 寫出 memory buffer 怎麼用 - Self-Refine (Madaan et al. 2023) — 對照 baseline,沒 episodic memory 的版本
Reference 實作: - noahshinn/reflexion — paper 第一作者的 reference 實作(含 episodic memory 完整流程) - LangChain — Reflexion — LangGraph 版本,跟本 stage 練習 4 RAG pipeline 直接接得起來 - mem0(已在上面列)+ Letta(已在上面列)— 可上線使用的 memory layer,可以直接當 Reflexion 的 episodic store
💡 跟 Stage 3 反思的分工: - 想理解「反思 loop 怎麼運作、單次怎麼跑」→ Stage 3 反思 - 想理解「反思怎麼跨 session 累積、agent 怎麼從過去學教訓」→ 本節 - 想看 production agent 內怎麼用反思(Cursor / Claude Code)→ Stage 5 5.7 Harness Internals
🤔 進階 Reasoning / Reflection — 2024-2026 思潮 ⭐ 兩個 track 都看¶
Reflexion 是 prompt-based reflection——LLM 在 inference 時自己改自己。2024-2025 出現了第二條路:訓練時就把 reflection 練進 model(OpenAI o1 / DeepSeek R1)。兩條路你都該知道。
Path 1:Prompt-based reflection / reasoning(傳統做法)¶
| 技巧 | 核心想法 | Paper |
|---|---|---|
| Self-Consistency | sample N 條推理、多數決 — 最簡單 + 最常用 | Wang et al. 2022 |
| Tree of Thoughts (ToT) | reasoning 變樹、可分叉可回溯、適合 puzzle / planning | Yao et al. 2023 |
| Graph of Thoughts (GoT) | 不只樹、可任意合併分支 | Besta et al. 2023 |
| Chain-of-Verification (CoVe) | 生答案 → 對自己提驗證題 → 改答案 | Dhuliawala et al. 2023 |
| CRITIC | tool-augmented self-critique(用 search / calculator 驗) | Gou et al. 2023 |
| Self-Discover | agent 先「發現」該用什麼 reasoning structure 再執行 | Zhou et al. ICML 2024 ⭐ 2024 |
| Self-Refine / Reflexion | 已在上面 / Stage 3 講 | Stage 3 反思、本 stage Reflexion |
Path 2:Trained-in reasoning / reflection(2024-2026 大轉折)¶
📺 視覺學習:李宏毅 2025 第七講 — DeepSeek-R1 這類大型語言模型是如何進行「深度思考」(Reasoning) 的?(NTU 生成式AI時代下的機器學習 2025)
OpenAI o1(2024-09)開啟、DeepSeek R1(2025-01)開源化、DeepSeek-V4-Pro(2026-04 preview、agent-focused 開源 reasoning)+ Claude Fable 5(2026-06、Mythos-class、位階在 Opus class 之上;存取已於 2026-06-12 暫停、目前無法使用)+ Claude Opus 4.8(2026-05、Opus class 旗艦、目前可用的最高層級、Dynamic Workflows + parallel subagent)+ GPT-5.5(2026-04)+ Gemini 3.1 Pro(2026-02)為當前 frontier(2026-06 後半另有 GPT-5.6 Sol / Terra / Luna 限量 preview 與 Gemini 3.5 Flash 陸續登場)——把「step-by-step thinking + 自我糾錯」訓練進 model 權重、inference 時自動展開長 reasoning chain(thinking tokens)。這是 2024-2026 LLM 最大典範轉移、目前所有 frontier model 都走這路。下表只列當前(2026-06)frontier——歷史前身(o1 / R1 / Sonnet 4.5 / Gemini 2.5)省略、想看 lineage 看每家發布日列。
| Model | 來源 / 發布 | 特色 | 連結 |
|---|---|---|---|
| GPT-5.5 | OpenAI 2026-04(前身:o1 2024-09 → o3 → GPT-5 2025-08 → 5.4 2026-03) | 閉源、reasoning + chat 合併、Thinking budget API、agent 能力強化。較新層級:GPT-5.6(Sol / Terra / Luna)、2026-06 限量 preview | OpenAI |
| Claude Fable 5 | Anthropic 2026-06(Mythos-class、位階在 Opus class 之上;同步發布 Claude Mythos 5 為解除部分 safeguard 的限量版本) | 閉源、Mythos-class(位階在 Opus class 之上)。⚠️ 存取已於 2026-06-12 被美國出口管制指令暫停(狀態頁);Fable 5 與 Mythos 5 目前皆無法使用、無恢復時程、請改用 Opus 4.8。 官方 benchmark 數字始終未公布 | Claude Fable 5 / Mythos 5 |
| Claude Opus 4.8 | Anthropic 2026-05(前身:Sonnet 4.5 / Opus 4.5 / Opus 4.7、Dynamic Workflows 研究預覽) | 閉源、Opus class 旗艦、目前可用的最高 Claude 層級(原為 Fable 5 的 safeguard fallback;Fable 5 已於 2026-06-12 暫停)、可控 thinking budget(API 參數)、SWE-bench / Terminal-bench 領先 | Anthropic extended thinking |
| Gemini 3.1 Pro | Google 2026-02(前身:Gemini 2.5 Thinking 2025、Gemini 3 2025-11) | 閉源、可看 thinking trace、GPQA Diamond 94.3%、價格 / 速度 / multimodal 領先。較新層級:Gemini 3.5 Flash、2026-06 已開放(3.5 Pro 開發中) | Gemini API |
| DeepSeek-V4 / V4-Pro / V4-Flash | DeepSeek 2026-04 preview(前身:R1 2025-01 → V3.1) | 開源 MIT license、agent-focused 訓練、推理 + 工具使用 + 知識處理整合、R 系列 reasoning 已併入主線 | HF DeepSeek-V4-Pro、R1 paper(方法 baseline)、CNBC report |
| QwQ-32B / QvQ-72B | Alibaba Qwen 2024-11 ~ 2026 | 開源 Apache 2.0、32B 在小尺寸 reasoning 仍是不錯的選擇、QvQ 是視覺版本 | QwQ blog |
兩條路怎麼選¶
| 你的情況 | 建議 |
|---|---|
| 用一般 chat model base、想加 reasoning | Path 1(prompt-based)—— ToT / Self-Consistency / CoVe |
| 預算 / latency 允許、要最強 reasoning | Path 2 —— GPT-5.5 / Opus 4.8 / Gemini 3.5 Flash / Grok 4.3 / V4-Pro 任挑一個(Claude Fable 5 已於 2026-06-12 暫停) |
| 想自己 fine-tune reasoning model | Path 2 —— 讀 R1 paper(方法 baseline)、從 R1-Distill / V4 開源權重起步 |
| 想 on-device / 預算極緊 | QwQ-32B(Apache 2.0)或 R 系列 distill |
| Multi-agent debate / critic 場景 | Path 1(CRITIC / debate)+ Stage 7 multi-agent |
💡 2025-2026 觀察: - reasoning model 把 Reflexion 那套吞進權重——但 prompt-based reflection 沒被取代:agent loop(控制反思時機 / 內容)+ multi-agent debate 還是必須的 - 2026 開源逼近閉源——DeepSeek-V4-Pro(2026-04 preview、MIT license)把 R1 reasoning 併入主線、agent-focused 訓練、跟 GPT-5.5 / Gemini 3.5 Flash 差距持續縮小 - agent capability 變主訴求——V4 / Opus 4.8 都把 agent-as-product(SWE-bench / Terminal-bench / tool use)當 headline benchmark、單純 reasoning 已經不夠賣 - 兩條路會長期共存、production agent 兩個都用
📏 RAG / Memory Eval — 跑得起來 ≠ 跑得準¶
為什麼這節重要:RAG / Memory 系統最大的坑是「看起來能跑、實際 retrieval 精度爛」。沒 eval、你不會知道改 chunk size / 換 embedding / 加 reranker 是不是真的有幫助——只會看到「答案好像比較順」這種主觀印象。Production agent 沒 eval 等於沒測試。
3 個核心 metric:
| Metric | 量什麼 | 工具 |
|---|---|---|
| Retrieval Recall@K | top-K 撈到的 chunk 裡有沒有 ground truth 答案的 chunk | ragas / TruLens / LangSmith |
| Answer Faithfulness | 生成答案是不是 grounded 在 retrieved chunk(vs 模型 hallucinate) | ragas / TruLens |
| Answer Relevance | 答案跟 query 相關度(避免答非所問) | ragas / LLM-as-judge |
代表 framework:
- explodinggradients/ragas ★ 13.9k Apache-2.0 ⭐ — RAG evaluation 標準工具、含 8+ metric(faithfulness / answer relevance / context precision / context recall 等)、支援 reference-free + reference-based eval
- TruLens — observability + eval 一起、LangChain / LlamaIndex 整合好
- LangSmith — LangChain 官方 eval + tracing、closed-source SaaS
怎麼開始:跑完 動手練習 4(完整 RAG pipeline)後、加上 ragas eval、measure 一次 baseline——再回頭調 chunk / embedding / top-k、看數字怎麼動。沒這一步、調參全是猜。
→ Stage 7 Eval 接續本節、把 eval 擴到 multi-agent / full harness。
🛠 動手練習(基礎 illustrative 練習)¶
練習 1:Embeddings¶
把 100 個句子做 embedding,找出某個 query 的最近鄰。理解 vector 之間的距離意義。
練習 2:Vector DB¶
把 embedding 存進 Chroma,做語意 query。比對「跟 keyword search 差在哪」。
練習 3:Chunking 對照¶
拿同一份文件做三種切法:固定長度、段落切法、heading-aware 切法。用 5 個真實問題比較 top-k 結果,記錄哪種切法比較容易撈到正確上下文。
練習 4:完整 RAG 流水線¶
把一份 PDF 切塊 → embed → 取 top-k → 生成回答。這是大多數 RAG 應用的基本骨架。
練習 5:Long-term Memory¶
讓 agent 在多輪對話之間記得事情。可以用 mem0 或自己用 vector store 接。
🎯 常用 Memory / RAG 工具推薦(按用途分類)¶
不知道從哪裡開始挑工具?下面是 2025 後段業界常用搭配——挑入口看「場景」、想深入點連結看 repo:
| 場景 | 推薦工具 | 為什麼 |
|---|---|---|
| 第一次跑 RAG(最快上手) | Chroma + LlamaIndex | local-first、零 ops、quickstart 友善。Stage 6 練習預設 |
| 企業級 RAG framework(LangChain / LlamaIndex 之外第 3 選擇) | Haystack (deepset) ★ 25.2k Apache-2.0 | deepset 開源、production-oriented orchestration、enterprise NLP 場景成熟 |
| agent 長期記憶(見 3 主流 memory layer) | agentmemory / mem0 / Letta / Zep / LangMem | 詳見上方 5 個主流 可上線使用的 memory layer 區塊 |
| RAG / Memory eval(必裝、見 RAG Eval) | ragas ★ 13.9k | RAG 評估標準工具、faithfulness / context recall / answer relevance 8+ metric |
| production scale RAG(百萬 doc) | Qdrant + LlamaIndex | Rust 寫的 vector DB、scale 大時比 Chroma 快 |
| 已有 Postgres 的環境 | pgvector | Postgres 擴充、SQL + vector 一起、運維最簡 |
| 企業級 RAG + Web UI | RAGFlow | document parsing 強(含 OCR / 表格 / layout)、企業場景、含 Web UI |
| 中文 RAG 範本 | Langchain-Chatchat | 中文圈最完整、本機 LLM 整合好(ChatGLM / Qwen / Llama) |
| 進階:Contextual Retrieval | Anthropic cookbook | Claude 搭配 prompt caching 的 contextual chunking(詳見上方 進階 RAG 技巧) |
| 進階:knowledge graph 推理 | LightRAG / Microsoft GraphRAG | knowledge graph + RAG、entity-relation 推理(詳見上方 進階 RAG 技巧) |
| 跨主題 tutorial 集 | ai-engineering-hub | RAG + agent 教學 collection、Jupyter notebook 形式 |
建議入手順序: 1. 第一個必裝:Chroma + LlamaIndex(跑 Stage 6 練習) 2. agent 要記事:加 mem0(最簡單的 memory layer) 3. 開始 production-scale:換成 Qdrant 或 pgvector 4. 想升級到進階 RAG:看上方 進階 RAG 技巧 三個 subsection
🎯 精選 Projects(範本 / spec / 範例 collection)¶
按用途分類、17 個項目一張表搞定。挑入口看「適合誰」、想深入點連結看 repo。
| 分類 | Project | ⭐ | 適合誰 | 為什麼推薦 / 備註 |
|---|---|---|---|---|
| RAG framework (完整流水線) |
LlamaIndex | ⭐⭐⭐⭐⭐ | 以文件為主的應用 | 以 RAG 為核心、document loader / chunking / retrieval / query engine 一條龍。★ 49k+ |
| infiniflow/ragflow | ⭐⭐⭐⭐⭐ | 要把 RAG 真的 ship 給非開發者用 | production 等級 RAG engine、深度文件理解(layout / 表格 / OCR)+ hybrid retrieval + agent loop + Web UI。★ 79k+、Apache-2.0 | |
| HKUDS/LightRAG | ⭐⭐⭐⭐ | 想看研究級 graph + long-context memory 方法 | graph + vector hybrid retrieval + summarization-based memory、EMNLP 2025 paper-backed。★ 34k+、MIT。研究風格 codebase | |
| Vector DB (local-first) |
Chroma | ⭐⭐⭐⭐⭐ | 練習 2 / 4、最容易上手的 vector DB | 開源 embedding 資料庫、本機跑、in-memory / SQLite 後端、零 ops。★ 27k+、Apache-2.0。安裝:pip install chromadb |
| Vector DB (production scale) |
Qdrant | ⭐⭐⭐⭐⭐ | Chroma 跟不上時、需要 production scale | Rust 寫的 vector DB、有雲端版跟自架版。★ 31k+ |
| Vector DB (hybrid) |
Weaviate | ⭐⭐⭐⭐ | production 部署 + schema 約束 | 內建模組(text2vec / generative / classification)、schema 驅動、內建 BM25 + vector hybrid。★ 16k+ |
| Vector DB (已有 Postgres) |
pgvector | ⭐⭐⭐⭐ | 原本就在用 Postgres 的團隊 | Postgres 擴充、SQL + vector 同一個 DB、運維最簡。★ 21k+ |
| Vector DB (跑在 app 內) |
lancedb/lancedb | ⭐⭐⭐⭐ | 想要 vector DB 直接內建、不想另跑 server | 直接跑在你 app 裡的 vector DB(不用另開 server)、能處理文字 + 圖片、關鍵字 + 向量一起搜。★ 10k+、Apache-2.0 |
| Memory framework (auto fact extraction) |
mem0ai/mem0 | ⭐⭐⭐⭐⭐ | 個人助理 / chatbot 需要 user-level memory | 自我精煉 memory 層、跨 session 儲存事實。★ 59k+ |
| Memory framework (OS-paging) |
Letta(前身 MemGPT) | ⭐⭐⭐⭐ | context 要跑很久的 agent(以月為單位) | 階層式 memory(working / archival)、OS-paging 概念。★ 22k+ |
| Memory(in-framework) | LangChain — Memory | ⭐⭐⭐ | 已用 LangChain | 4 種 memory 抽象(buffer / summary / vectorstore-backed / entity) |
| 進階 RAG 技巧 | Anthropic — Contextual Retrieval cookbook | ⭐⭐⭐⭐⭐ | 跑完基本 RAG 想升級 | Claude 搭配 prompt caching 的 contextual chunking、含完整端到端範例 |
| 中文 RAG 樣板 | chatchat-space/Langchain-Chatchat | ⭐⭐⭐⭐ | 中文知識庫 / RAG 應用 | 中文社群最廣泛使用、可離線部署、中文預設好、支援 ChatGLM / Qwen / Llama / Ollama。★ 38k+、Apache-2.0。⚠️ 最後更新 2025-11(邊緣) |
| 教材合集 | patchy631/ai-engineering-hub | ⭐⭐⭐⭐ | 想看「同概念在不同情境怎麼實作」 | 主題式 LLM / RAG / agent tutorial 集、Jupyter notebook、跨多個 stage 都用得上。★ 34k+、MIT |
| Production AI assistant (學 ship RAG 的 reference) |
onyx(前身 Danswer) | ⭐⭐⭐⭐⭐ | 想看「RAG-driven AI assistant 怎麼 production 化」 | 開源企業級 AI assistant、跨 LLM 支援、含完整 ingest / retrieval / chat / admin。★ 29.4k、active 維護 |
| RAG cookbook (30+ 技巧範例) |
NirDiamant/RAG_Techniques | ⭐⭐⭐⭐⭐ | 跑完基本 RAG、想看各種變體 | 大型 RAG 技巧 cookbook、含 Self-RAG / HyDE / Multi-Query / Adaptive 等 30+ Jupyter notebook 範例 |
| DSPy (programming not prompting) |
stanfordnlp/dspy | ⭐⭐⭐⭐⭐ | 用 LLM 一段時間、想自動 optimize prompt + chain | Stanford NLP group、★ 34.4k MIT、Path 3 paradigm(詳見 進階 RAG DSPy) |
| RAG / Memory Eval (必裝) |
explodinggradients/ragas | ⭐⭐⭐⭐⭐ | 跑完 Stage 6 練習 4、想 measure retrieval 精度 | RAG eval 標準工具、8+ metric、reference-free + reference-based。★ 13.9k Apache-2.0 |
✅ 進入 Stage 7 前的自我檢查¶
你能不能:
- 寫一條 50 行的 RAG 流水線(load → chunk → embed → store → query → answer)
- 解釋為什麼天真的切塊在長文件上會失敗
- 針對 API 文件、PDF、表格設計不同的 chunking 策略
- 在某個規模下,能在 Chroma、Qdrant、pgvector 之間做出選擇
- 區分「給 agent memory」跟「用 RAG」這兩件事
- 解釋 RAG 跟 Memory 各補哪段(從上面 從 RAG 到 Memory 表)
如果都可以 → 前往 Stage 7 — Multi-Agent · 進階應用。