Stage 6 — Context Engineering: RAG and Memory¶
⏱ Estimated Time: 2 weeks (approx. 10 hours)
💡 This stage is dense with terminology (RAG / vector databases / embedding / chunking / hybrid search / reranking...) — if unfamiliar, first consult
resources/glossary.md3.📋 Chapter Structure: Positioning → Entry Point → RAG Core (Basics + Advanced + DSPy + Eval) → Bridge → Memory Core (3 patterns + trio + advanced) → Chunking → Reflexion / Reasoning → Practice → Projects
🔑 Key Terms: See
resources/glossary.md3 (memory / RAG / embedding / chunking / reranking)
This stage is not about memorizing more terminology. It is about understanding how agents manage context.
- RAG answers: what data should be retrieved from an external knowledge base right now?
- Memory answers: what should an agent remember across conversations, sessions, and tasks?
- Context Engineering is the higher-level question: before each LLM call, what information should be assembled into the prompt so the model can make the right decision inside a limited context window?
→ This connects directly to Stage 7's three engineering layers: Prompt = how to ask on this call / Context = what information to include on this call / Harness = how the whole agent system runs. This stage is the middle layer.
The two context capabilities an agent needs¶
- Retrieval: pulling task-relevant information from an external knowledge base.
- Memory: preserving state, preferences, and experience across conversations, sessions, and tasks.
RAG (Retrieval-Augmented Generation) is the most common retrieval architecture today. Memory is what lets an agent remember the user, task history, and its own past experience. This chapter treats them separately so "looking things up" and "remembering things" do not get mixed together.
Separate the terms first: Retrieval / RAG / Vector Store / Memory are not the same thing¶
| Term | Do not confuse it with | Plain-language explanation |
|---|---|---|
| Retrieval | All of RAG | The act of finding information |
| RAG | Vector DB | The full retrieve + generate workflow |
| Embedding | Memory | Turning text into vectors so similarity search becomes possible |
| Vector store | RAG | The place where embeddings are stored and searched |
| Chunking | Retrieval itself | Splitting documents into searchable pieces |
| Memory | RAG | Persistent management of user, task, and experience data |
🎯 What is Context Engineering? (Positioning)¶
In one sentence: Context Engineering = deciding what information to put into the window the LLM can see on each call.
The point is not "how many conversations you opened." The point is "what you put into each one." Karpathy's June 2025 tweet puts it best: the delicate art of putting just the information useful for the next step into the window.
📺 Visual Learning: Hung-Yi Lee 2025 Lecture 2 — Context Engineering: The Key Technology Behind AI Agents (NTU Introduction to Generative AI & Machine Learning 2025)
Where it sits in the three-layer stack¶
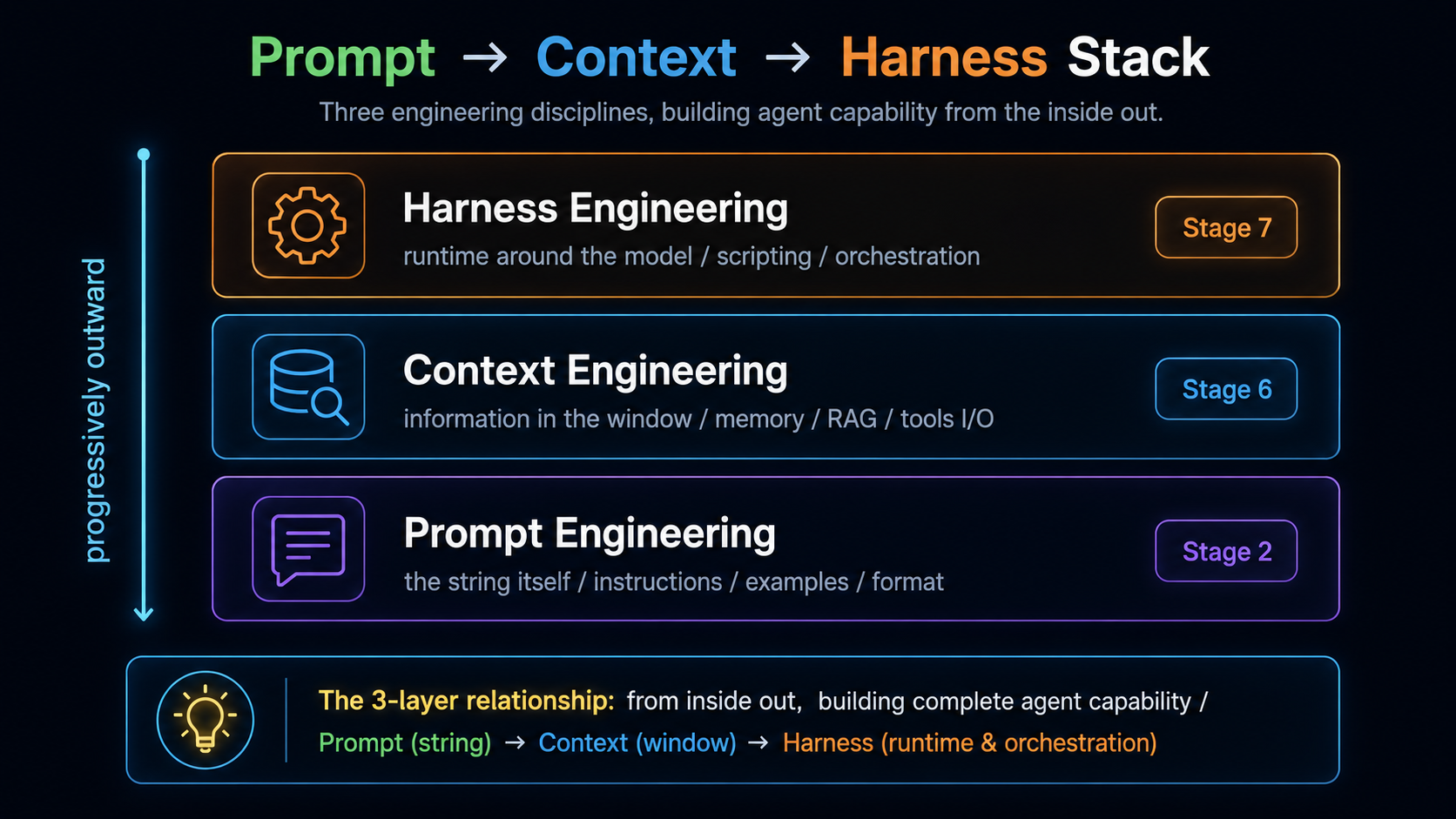
See Stage 2 for the full comparison.
This stage covers 2 of the 4 sub-problems (Lance Martin 2025 framing)¶
| Sub-problem | What it solves | Concrete example | Covered in this stage? |
|---|---|---|---|
| Select | Which external information should be pulled into the window | User asks "Which cafe near me is good?" → pull 3 highly rated places from a Yelp DB → put them into the prompt | ✅ Core theme (RAG / vector search / GraphRAG) |
| Write | Which interactions / lessons should be written into long-term memory | User said last week "I eat vegan" → write it to memory; when they ask for restaurant suggestions again, retrieve it so you do not recommend meat | ✅ Core theme (memory layers) |
| Compress | How to compress an overlong conversation | 50 turns exceed 200k tokens → auto-summarize the first 40 turns, keep the last 10 turns verbatim | ⚠️ Partial (here + Stage 7 Harness context manager) |
| Isolate | How to split windows across multiple agents | The supervisor sees the whole picture, workers only see their own slice, and they do not interfere with one another | ❌ Covered in Stage 7 multi-agent |
Four concepts commonly mixed up¶
| Term | What it is (abstract / concrete) | Example tools |
|---|---|---|
| Memory | An agent's capability to remember things across conversations / sessions (abstract concept) | LangChain ConversationBufferMemory / mem0 / Letta |
| Embedding | Turning text into an N-dimensional vector so similarity becomes computable (data transformation) | sentence-transformers producing 768-dim vectors / OpenAI ada-002 |
| Vector DB | The storage layer for storing + querying embeddings (infrastructure) | Chroma / Qdrant / Weaviate / pgvector |
| RAG | The architectural pattern of "retrieve relevant snippets → insert into prompt → generate" | LlamaIndex / LangChain RAG chain |
→ Core distinction: Memory is a capability, Embedding is data transformation, Vector DB is storage, and RAG is an architectural pattern. These four are often confused, but they belong to different layers.
RAG vs Long Context vs Fine-tuning — when to use what¶
LLMs can use your private / domain data in three main ways. This stage teaches RAG, but you should know when not to use it:
| Option | Suitable for | Not suitable for | Cost |
|---|---|---|---|
| RAG (external retrieve) |
Large / dynamic / private knowledge bases, citation-heavy use cases | Tasks requiring full-text reasoning, cross-document multi-hop reasoning | One extra vector-search latency per query |
| Long Context (directly in prompt) |
Medium-sized documents under 200k tokens, one-off queries, cross-document reasoning | Large / frequently changing knowledge bases, citation-heavy use cases | High input-token usage per query, even with prompt caching |
| Fine-tuning (modifying model weights) |
Consistent style / format, specific domain language (medical, legal, code) | Knowledge that changes, use cases requiring citations, cases where you do not want to train a model | Training + maintenance + model lock-in costs |
→ How to choose: start with RAG (lowest cost, easiest to change) → if RAG is insufficient, consider Long Context → if both fail, consider Fine-tuning. Proceed to Stage 7 to learn fine-tuning deployment.
📌 Learning Objectives¶
- Build a basic RAG pipeline (chunk → embed → store → retrieve → generate)
- Identify where RAG should and should not be used
- Differentiate between working memory, long-term memory, episodic memory, semantic memory, and procedural memory
- Understand vector embeddings and similarity search
- Know when to add advanced RAG techniques (GraphRAG / Contextual Retrieval / Hybrid Search)
🚪 Prerequisites¶
You should have already:
- Completed Stage 3 (ability to write tool use, call LLM APIs, understand ReAct loop) — hard technical prerequisite
- Walked through Stage 4 (agent frameworks) + Stage 5 (Claude Code ecosystem) — the curriculum main line is 3 → 4 → 5 → 6 (see the README learning map); not a hard technical prerequisite, but RAG / memory often pairs with frameworks + Claude Code memory mechanisms so following the sequence gives a more complete understanding, and Stage 7 expects you to have completed 4 + 5 + 6
- Be able to run Python pip install to install SDKs (will use chromadb, sentence-transformers, etc. later)
- Be comfortable with basic Python structures like lists, dicts, and generators.
If not, refer back to Stage 3 or Stage 0 Setup Guide.
📚 Required Reading¶
- LlamaIndex — RAG Concepts — The clearest introduction.
- LangChain — RAG Tutorial — Hands-on implementation.
- Pinecone — Learning Center — Vector DB fundamentals.
- Anthropic — Contextual Retrieval — Anthropic's approach to RAG with prompt caching.
- LangChain — Text Splitters — Introduction to chunking strategies.
🙏 Special Recommendation for the Memory Chapter: Refer to
datawhalechina/hello-agents— This stage covers the concepts and basic implementations of memory. For a chapter-length in-depth guide, consult the corresponding chapter in hello-agents, which provides the most comprehensive explanation of short-term vs. long-term memory differences, dynamic prompt assembly with context engineering, session persistence, and forgetting strategies. This stage serves as a roadmap, while that is a deep dive textbook.
🧭 Unit Guide (Progressive Flow)¶
This chapter proceeds by first teaching RAG, then Memory, as RAG is the most fundamental and commonly used tool for context engineering, while Memory enables agent capabilities across conversations/sessions. We'll start by getting the RAG pipeline running, then introduce Memory design, and finally revisit Chunking details.
Recommended Reading Order:
- 🌐 Basic RAG Pipeline (Next Section) — Establish the mental model.
- 🚀 Advanced RAG Techniques — GraphRAG / Contextual Retrieval / Hybrid Search, etc. for production upgrades.
- 🌉 From RAG to Memory — Why RAG isn't enough and where Memory fills the gaps.
- 🧠 Memory Design — Short-term vs. Long-term, 3 patterns, CoALA framework.
- 🧩 Chunking Details — In-depth look at techniques used in both RAG and Memory.
As you read this chapter, consider: In which application scenarios is RAG unsuitable? Which scenarios are suitable for RAG but not well-served by basic RAG? This will lead you to advanced techniques like GraphRAG / Self-RAG / RAPTOR later on.
🌐 Basic RAG Pipeline¶
RAG (Retrieval-Augmented Generation) = The pattern of "retrieve relevant snippets → insert into prompt → generate". Think of it as building a library for your agent—you need to organize your books first, then you can quickly and accurately retrieve information when needed.
The most basic RAG is divided into two pipelines:
- Data Preprocessing (Ingest Once): ingest → chunk → embed → store (index). This step builds the searchable knowledge base.
- Retrieval & Generation (Per Query): retrieve → generate. This step finds relevant content when the user asks a question and feeds it to the LLM for generation.
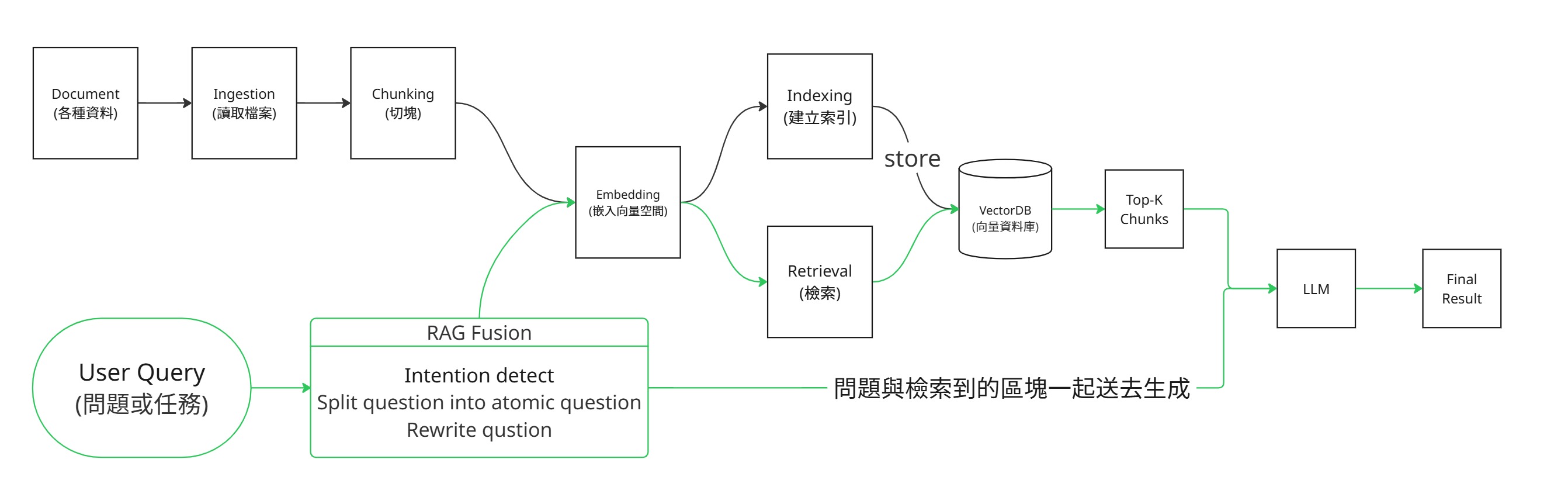
The RAG Fusion and query rewrite techniques mentioned in the diagram fall under advanced retrieval techniques. When learning RAG for the first time, focus on understanding the main flow.
Understanding the 5 Steps:
| Step | What it does | Which Pipeline | Technical Details Found In |
|---|---|---|---|
| 1. Ingest | Loads data (PDF / web / DB) | Preprocessing | LlamaIndex / LangChain respective loaders |
| 2. Chunk | Splits documents into small pieces (500-2000 tokens / chunk) | Preprocessing | See 🧩 Chunking Details later (read RAG/Memory main sections first, technical details later) |
| 3. Embed | Converts each chunk into an N-dimensional vector | Preprocessing | sentence-transformers / OpenAI ada-002 |
| 4. Store | Stores vectors + metadata in a vector DB | Preprocessing | Chroma / Qdrant / pgvector |
| 5. Retrieve + Generate | Embeds query → top-k semantic search → concatenates into prompt → LLM generates answer | Per Query | Universal LLM API |
These are the minimal structural elements. The 3 most common pitfalls:
- Chunk size too large / too small: If too large, retrieved chunks might contain only one relevant sentence amidst much noise; if too small, context is lost (see 🧩 Chunking Details).
- Incorrect embedding model chosen: Using an English model for Chinese documents halves retrieval accuracy.
- Top-k set too high / too low: Too low might miss relevant chunks; too high introduces noise / burns tokens.
📚 For more RAG pitfalls and solutions: NirDiamant/RAG_Techniques ★ Large Production RAG Cookbook, includes 30+ techniques + Jupyter notebook examples.
📄 The two places RAG actually breaks (don't only tune chunking): (1) parsing / ingest: PDF → clean markdown is where garbage-in starts: docling-project/docling (★61k, MIT), opendatalab/MinerU (strong on Chinese / scientific PDFs; AGPL, mind the license), microsoft/markitdown (★150k+, MIT). (2) picking an embedding model: your first retrieval-quality decision: check the MTEB leaderboard; for Chinese / multilingual, BGE-M3 (★12k, MIT) is a common pick.
After implementing the basic skeleton, complete Exercises 1-4 (Embeddings / Vector DB / Chunking / Full Pipeline) to gain practical experience, then move to the next section on Advanced RAG Techniques.
🚀 Advanced RAG Techniques (Read After Basic RAG)¶
The following six subsections represent common production RAG enhancements from 2024-2026, grouped by the stage they are added to the pipeline: - After Retrieve — GraphRAG / Contextual Retrieval / Hybrid Search & Reranking - Before Retrieve (Query Rewriting) — Query Transformations - During Retrieve (Control Flow) — Adaptive / Agentic RAG - Index Structure — RAPTOR - 2024-2026 Overview — 17 other techniques worth knowing
First, complete the basic RAG to establish a baseline version before diving into these—otherwise, you'll be tuning parameters without a baseline, never knowing which change yielded improvement.
| Technique | Solves What Problem | Pipeline Stage | Cost |
|---|---|---|---|
| GraphRAG | Vanilla RAG cannot perform multi-hop / cross-document entity-relation reasoning | Before Retrieve (build graph) + During Retrieve (graph traversal) | High (requires KG construction, significant LLM token usage for entity extraction) |
| Contextual Retrieval | Chunks lose original document context, retrieval fetches incorrect snippets | After Chunk / Before Embed (add contextual header) | Medium (one-time ingest cost, 90% cheaper with prompt caching) |
| Hybrid Search & Reranking | Pure vector misses keyword matches, top-k has noise | During Retrieve (combine with BM25) + After Retrieve (cross-encoder reranking) | Low (mature tools integrate easily) |
🔗 GraphRAG — Knowledge Graph + RAG¶
Mental Model: Vanilla RAG cuts documents into chunks and relies on embedding similarity for retrieval—but it doesn't know which entities are the same or their relationships. GraphRAG constructs a knowledge graph by extracting (entity, relation, entity) triples from documents during ingestion. Retrieval then uses both vector similarity and graph traversal to find related entities and their connections.
When to Use: - Tasks requiring multi-hop reasoning (A → B → C to answer). - Cross-document entity referencing (company financial reports, research papers, legal cases). - Questions like "How does X affect Y, and what is Y linked to Z?" — Vanilla RAG typically only retrieves content related to X.
When Not to Use: - Documents without entity-relation links (standalone FAQs, independent product manuals). - Small knowledge bases (< 1k chunks) — Vanilla RAG is sufficient. - Tight budgets — KG construction can be 10-50x more token-intensive than regular RAG.
Representative Frameworks: - HKUDS/LightRAG ★ 35.1k MIT EMNLP 2025 — Currently the hottest community choice, lightweight, KG + vector hybrid, lower cost than Microsoft's version. - Microsoft GraphRAG — Original reference implementation, Apache-2.0, includes community detection. - gusye1234/nano-graphrag — Minimal implementation (< 1000 lines) for understanding core principles.
Paper: From Local to Global: A Graph RAG Approach to Query-Focused Summarization (Edge et al. 2024) — Original Microsoft GraphRAG paper explaining how community summarization addresses global queries.
🪶 Contextual Retrieval — Anthropic's Prompt Caching Solution¶
Mental Model: Vanilla chunks lose original document context—a chunk like "Q3 revenue grew 15%" doesn't tell you which company or which year's Q3. Anthropic's 2024 proposal: During ingestion, use an LLM to generate a 50-100 token contextual header for each chunk (e.g., "This chunk is from ACME Corp 2024 Q3 earnings, discussing the cloud segment...") and prepend it before embedding. Combined with prompt caching, this allows sending the entire document + each chunk only once, sharing the cache for subsequent chunks.
When to Use: - Chunks are semantically distant from their original document's topic (financial reports, research papers, long narratives). - You are willing to incur an initial ingest cost for improved retrieval accuracy. - You are using Claude or plan to leverage prompt caching (other models can run this, but without cache benefits).
When Not to Use: - Chunks are self-contained (FAQs, product descriptions, definitions). - Knowledge base changes frequently (requires re-ingestion). - Extremely tight budgets — ingest cost is higher than vanilla, even with caching discounts.
Why it Saves 90% Cost: Anthropic's report suggests prompt caching reduces costs to ~1/10 by treating the entire document as a cached prefix and only sending differences for each chunk. However, this only saves on ingest, not retrieval.
Representative Implementations: - Anthropic — Contextual Retrieval Blog ⭐ — Official explanation + benchmark (failed retrieval rate dropped from 5.7% to 1.9%). - Anthropic Cookbook — End-to-end Jupyter notebook with prompt templates.
Paired Techniques: The same Anthropic blog also recommends combining this with Contextual BM25 (using contextual chunks with both vector + BM25) + reranking—leading into the next section on Hybrid Search & Reranking.
🎯 Hybrid Search & Reranking — Two Common Reinforcement Components for Production RAG¶
Mental Model: - Hybrid Search = Combines vector similarity (semantic match) with BM25/keyword search (literal match), using methods like RRF (Reciprocal Rank Fusion) to fuse scores. This addresses the dual blind spots of pure vector search: missing keyword matches due to different phrasing and weak semantic embedding for proper nouns, product IDs, technical terms, or rare words. - Reranking = First stage retrieves top-50 chunks (prioritizing recall, broad fetch) → then a cross-encoder reranker re-scores and ranks the top top-5 (prioritizing precision, fine-grained filtering). Cross-encoders (which process query + chunk together) are much more accurate than bi-encoders (query/chunk processed separately) but are too slow for initial retrieval, hence only used in the second stage.
Why These Are "Must-Add Polishes": Production RAG evaluations almost universally show that adding hybrid search + rerankers improves recall@5 from around 70% to 85-90% with low marginal cost and mature tooling. These offer the best cost/benefit.
When to Use: - Production RAG (not demos/experiments). - Queries containing proper nouns, product IDs, technical terms, or rare words (pure vector search might miss these). - Budget allows for an additional 100-300ms latency per query.
When to Defer: - Experimental phase / MVP (get basic RAG working first). - Extremely tight budget / latency constraints (rerankers add an extra model call).
Representative Tools:
- Hybrid Search: Weaviate (built-in BM25 + vector + RRF) / Qdrant (supports sparse + dense vectors) / pgvector + Postgres FTS.
- Rerankers: Cohere Rerank API (commercial, widely used) / BGE Reranker (open-source, HuggingFace, good performance in Chinese) / Jina Reranker.
- Framework Built-ins: LlamaIndex's SentenceTransformerRerank / LangChain's ContextualCompressionRetriever.
Paper / Introduction: - Pinecone — Rerankers and Two-Stage Retrieval — Best explanation of the reranker mental model. - Anthropic — Contextual Retrieval (listed above) — Demonstrates hybrid + reranker with benchmarks.
Query Transformations — HyDE / Multi-Query / RAG Fusion¶
Mental Model: Basic RAG embeds the user's query directly for retrieval—but the query's wording, style, or abstraction level often differs significantly from the document (e.g., user asks "What should I do for a stomach ache?", document describes "Differential diagnosis of upper abdominal pain"). Query transformations rewrite the query before retrieval, creating versions closer to how documents are phrased.
3 Representative Techniques:
| Technique | How it Rewrites | When to Use |
|---|---|---|
| HyDE (Hypothetical Document Embeddings) | First, let the LLM generate a "hypothetical answer" to the query; use the embedding of this answer for retrieval. | When query wording/style differs greatly from document phrasing. |
| Multi-Query | The LLM rewrites the query into N variations, each retrieved separately, then unioned and deduplicated. | When the query is too short, ambiguous, or has multiple meanings. |
| RAG Fusion | Combines Multi-Query with RRF to fuse results from N retrievals for more stable ranking. | Same as Multi-Query, aims for more stable rankings. |
When Not to Use: When the query is already long and structured (e.g., RAG over code, user pastes an error stack trace)—rewriting might introduce noise.
Papers / Implementations:
- HyDE (Gao et al. 2022) — Original paper.
- RAG Fusion (Raudaschl 2023) — Reference implementation for Multi-Query + RRF.
- LangChain includes MultiQueryRetriever / LlamaIndex includes HyDEQueryTransform built-in.
🔁 Adaptive / Agentic RAG — Self-RAG / CRAG / Adaptive RAG (2024 Focus)¶
Mental Model: All RAG techniques above assume a fixed pipeline: "query → retrieve → generate". Adaptive / agentic RAG turns this into an agentic loop where the LLM decides whether to retrieve, evaluates retrieval quality, and adjusts the query if necessary. This is a major focus of RAG research in 2024.
| Technique | How it Self-Corrects | Paper |
|---|---|---|
| Self-RAG | Trains the LLM to output [Retrieve] tokens to decide retrieval, then outputs [IsRel]/[IsSup]/[IsUse] scores for each retrieved segment. |
Asai et al. ICLR 2024 |
| CRAG (Corrective RAG) | A retrieval evaluator scores results; high confidence uses them directly, low confidence falls back to web search, medium confidence triggers query rewriting. | Yan et al. 2024 |
| Adaptive RAG | A classifier first determines query complexity, routing to strategies like "no retrieve / single-step / multi-step". | Jeong et al. NAACL 2024 |
Why This is a 2024 Focus: A fixed pipeline is suboptimal for both simple queries (e.g., "What is the capital of Tokyo?" doesn't need retrieval) and complex ones (multi-hop, cross-document). Letting the LLM decide routing handles both extremes effectively.
When to Use: Production RAG with diverse query types (from factual to reasoning), willing to accept 1.5-3x latency for increased accuracy. When Not to Use: Uniform query types / strict budget / extremely sensitive latency requirements.
Implementations: LangGraph provides official cookbooks for Self-RAG + CRAG + Adaptive RAG, which can be directly applied.
🌳 RAPTOR — Hierarchical Recursive Retrieval (ICLR 2024)¶
Mental Model: Basic chunking creates flat chunks—but the main thesis of a long document isn't contained in any single chunk. RAPTOR recursively clusters and summarizes chunks, building a multi-layer tree: bottom layer = original chunks, middle layers = summaries of related chunk groups, top layer = overall document summary. Retrieval can then search the entire tree or specific abstraction levels.
Why it's Useful: - Retrieves answers for abstract queries (e.g., "What is the main conclusion of this paper?"—the original chunks might not have this sentence, but the top-level summary does). - Retrieves specific details effectively (bottom chunks are preserved). - Unlike GraphRAG—RAPTOR uses a tree (hierarchical summarization), while GraphRAG uses a graph (entity-relation).
When to Use: Long documents (books, papers, reports) requiring queries at different levels of abstraction; coherent knowledge bases. When Not to Use: Independent chunks (FAQs); frequently changing knowledge bases (rebuilding the tree is costly).
Paper / Implementation:
- RAPTOR (Sarthi et al. ICLR 2024) ⭐ — Original paper.
- parthsarthi03/raptor — Official reference implementation.
- LlamaIndex has built-in RAPTOR pack.
🧬 DSPy — Programmatic Optimization Without Prompting (Path 3 Paradigm)¶
Mental Model: Traditional RAG/Agents involve manually writing prompts and chains. DSPy eliminates prompt writing—you define "signatures" (input/output types) and write programs (chain structures); DSPy then compiles the optimal prompts, few-shot examples, and retriever settings using LLMs. Proposed by Stanford NLP group in 2024 and championed by Karpathy, it's increasingly adopted in production.
When to Use: - Your RAG prompts have accumulated over 6 months and are hard to maintain; you want automatic optimization. - The same program needs to switch between different LLM providers (DSPy recompiles automatically). - Your agent system has multiple steps; you want to track metrics and traces.
When Not to Use: - You only have one prompt and don't need optimization. - You are new to LLMs and haven't explored prompting yet.
Representative Repo: stanfordnlp/dspy ★ 34.4k MIT, official Stanford NLP group, actively maintained.
How it Integrates with RAG: DSPy is compatible with all RAG techniques discussed—you can use GraphRAG / Hybrid Search / Reranking as DSPy modules and compile them. It's an overarching typing system for RAG construction.
→ Parallel to Path 1 / Path 2 Reasoning: Path 1 is "manual prompt writing", Path 2 is "training reflection into model weights", DSPy is Path 3 "programmatic search for optimal prompts". It's especially useful for advanced scenarios in Stage 7 Multi-agent.
📊 Overview of Advanced RAG Techniques — 2025-2026 Main Themes ⭐¶
Advanced RAG research in 2024-2025 is converging on 3 main themes:
- 🧠 Merging KG + Memory — Moving from flat vector stores to "structured, evolving, associative" knowledge representations. Representatives: HippoRAG 2 (Hippocampus-inspired, KG + PageRank, cross-document multi-hop), A-MEM, KAG.
- 🎬 Multimodal RAG — Moving from text retrieval to native image / video / table retrieval. Representatives: ColPali (direct image embedding from PDF pages, bypassing OCR), TV-RAG, MegaRAG.
- 🤖 Agentic RAG — Retrieval evolves from a fixed pipeline into a tool within an agent loop (the agent decides how many times and how to retrieve). Representatives: A-RAG, Self-RAG (covered in Adaptive / Agentic RAG).
2 Other Areas Worth Exploring: - 🛡 RAG Security — Corpus poisoning / prompt injection become critical in production considerations. Representatives: RAGPart / RAGMask. - 🔧 Prompting is Dead — Systems automatically search for optimal prompt + retriever combinations. Representatives: DSPy (Stanford's "programming not prompting" paradigm, see DSPy subsection above).
5 Representative Works for Deep Dive (quick reference):
| Technique | One-Liner | Link |
|---|---|---|
| HippoRAG 2 | KG + Personalized PageRank, cross-document multi-hop, hippocampus-inspired | Gutiérrez et al. ICML 2025, OSU-NLP-Group/HippoRAG ⭐ |
| ColPali | Direct image embedding from PDFs, bypassing OCR, multimodal RAG entry point | Faysse et al. 2024 |
| A-RAG / SoK Agentic RAG | Retrieval as a tool, agent decides retrieval frequency/method | Ayanami0730/arag, SoK survey ⭐ |
| DSPy | No prompt writing, program + signature for auto-optimization | stanfordnlp/dspy ★ 34.4k |
| LightRAG | Lightweight alternative to MS GraphRAG, EMNLP 2025 | HKUDS/LightRAG ★ 35.1k (already in GraphRAG section) |
📚 Full Overview — 12 Other Advanced RAG Techniques Worth Knowing (Expand to View)
| Technique | One-Liner | Year / Paper | |---|---|---| | **Sentence-Window Retrieval** | Embed sentences, retrieve +/- N sentence window | Built into LlamaIndex | | **Parent-Child / Small-to-Big** | Embed small chunks, retrieve parent chunks | LangChain `ParentDocumentRetriever` | | **Multi-Vector Retrieval** | One chunk, multiple embeddings (summary / original / hypothetical question) | LangChain `MultiVectorRetriever` | | **ColBERT / Post-Interaction Retrieval** | Token-level comparison instead of pooled embeddings | [Khattab & Zaharia 2020](https://arxiv.org/abs/2004.12832), [RAGatouille](https://github.com/AnswerDotAI/RAGatouille) | | **LongRAG** | Large chunks (4k) + long-context reader, reduces retrieval frequency | [Jiang et al. 2024](https://arxiv.org/abs/2406.15319) | | **MemoRAG** | Memory model compresses KB into latent memory, retrieval triggered by cues | [Qian et al. 2024](https://arxiv.org/abs/2409.05591) | | **KAG** (Knowledge-Augmented Generation) | Strict schema KG + logical reasoning, finance / medical / legal domains | [Liang et al. 2024 (Ant Group)](https://arxiv.org/abs/2409.13731) | | **MiA-RAG** (Mindscape-Aware) | First build high-level document summaries (mindscape) to guide retrieval and answers | [arXiv:2512.17220](https://arxiv.org/abs/2512.17220) ⭐ 2025-12 | | **QuCo-RAG** (Quality-Controlled) | Uses pretraining statistics to determine if retrieval is needed; rare entity triggers search, reducing hallucination | [arXiv:2512.19134](https://arxiv.org/abs/2512.19134) ⭐ 2025-12 | | **MegaRAG** | Multimodal KG, extracts entities + relations + visuals from long documents, builds hierarchical graphs | [arXiv:2512.20626](https://arxiv.org/abs/2512.20626) ⭐ 2025-12 | | **TV-RAG** | Training-free time-aware RAG, aligning long videos with subtitles + visuals | [arXiv:2512.23483](https://arxiv.org/abs/2512.23483) ⭐ 2025-12 | | **RAGPart / RAGMask** | Lightweight defense against RAG corpus poisoning attacks | [arXiv:2512.24268](https://arxiv.org/abs/2512.24268) ⭐ 2025-12 |🌉 From RAG to Memory — Why RAG Isn't Enough¶
By now, you should be able to run basic RAG and understand several production levers. However, looking back at the 3 problem domains listed in Context Engineering—you've only addressed Retrieval, and haven't touched Memory Management. Why are these treated separately?
RAG addresses "retrieve relevant snippets from external knowledge bases"—but agents also need to "remember things themselves across conversations / sessions". These are not the same problem:
| Dimension | RAG | Memory |
|---|---|---|
| Content Source | External (PDFs / documents / web / DB) | Agent's own conversations / experiences |
| Writing Time | Ingested once, retrieved repeatedly | Written every turn, potentially at every task |
| Content Nature | Primarily static facts, documentary knowledge | Dynamic: user preferences, past interactions, accumulated lessons |
| Can it Replace RAG? | — | No—you wouldn't treat every PDF as "memory" |
| Can it Be Replaced by RAG? | — | No—RAG won't "remember what the user said last time" |
3 Scenarios Where RAG Is Insufficient (Corresponding to Memory's Role):
- Remembering User Preferences / Persona Across Sessions—User told the agent "I'm vegan" last week; this week, the agent remembers not to recommend meat dishes. RAG knowledge bases don't update this automatically.
- Accumulating Agent's Past Success/Failure Lessons (Reflexion's domain)—An agent fails a task the first time, reflects on "why it failed," stores this, and retrieves it on similar future tasks to avoid repeating mistakes. RAG knowledge bases don't "remember its own failures."
- Intermediate States in Long-Horizon Tasks—An agent running a 100-step task needs to retain working memory without loss. RAG is not suitable for this type of "short-term + structured + high-frequency writing" state.
→ Conclusion: RAG and Memory are complementary, not mutually exclusive. Production agents typically need both: RAG for external knowledge, Memory for self-reflection and user interaction history. The next section, Memory Design, will guide you in choosing the right memory pattern.
🧠 What is Memory + How to Design It¶
📺 Visual Learning: Hung-Yi Lee 2025 Lecture 2 — Understanding AI Agent Principles in One Lecture (Includes Read / Write / Reflection memory modules) (NTU Machine Learning in the Era of Generative AI 2025)
Working memory vs. long-term memory — two time scales¶
| Aspect | Working memory / short-term context | Long-term memory / persistent memory |
|---|---|---|
| Chinese term | 工作记忆 / 短期上下文 | 长期记忆 / 持久记忆 |
| Core meaning | Information visible during this task or this conversation | Information stored externally and retrievable across sessions later |
| Duration | Short, usually limited to the current session | Long, can span sessions |
| Technical basis | Context window / prompt | Memory store / user profile / vector database |
| Best for | Task details, what was just said | Stable preferences, long-term goals, background knowledge |
| Limited by context length? | Yes, because the model can only see a limited amount at once | Much less, because it can be stored externally and only a relevant slice gets retrieved |
| Real-world analogy | A verification code you just received, the previous sentence in an active conversation | Knowledge you have deeply learned, a library, a knowledge base, books you have read |
→ In agents, "short-term memory" is more precisely working memory. It is not external storage; it is whatever is currently visible inside the prompt / context window.
Episodic / Semantic / Procedural memory — three content types¶
Important: working / long-term is a time axis. The three categories below are a content axis. The two classifications are orthogonal, not mutually exclusive. Long-term memory can contain episodic + semantic + procedural memory at the same time.
| Type | Meaning | Core idea |
|---|---|---|
| Episodic memory | Experience memory | Concrete past tasks, interactions, or failures |
| Semantic memory | Fact memory | Stable knowledge, user preferences, background facts |
| Procedural memory | Skill memory | Rules, tools, workflows, and skills for how the agent acts |
→ These three types map to the CoALA framework. Reflexion is a classic episodic-memory pattern because it accumulates success / failure lessons from prior trials.
Here, a "session" can be understood as one continuous interaction: a chat, a task run, or a single agent execution.
3 design patterns (when to use what) ⭐ Essential for Track B¶
Not all agents need an external memory store. Choosing the wrong memory architecture can cost 10x more tokens for the same result.
This is the mental model to establish before starting the exercises. The exercises below focus on Pattern 3 (vector store), but production systems may not need that much complexity.
| Pattern | Suitable scenarios | How it works | Cost |
|---|---|---|---|
| 1. Naive buffer (stuff everything into context) |
Short conversations, ≤ 10 turns, no cross-session memory requirement | Send the entire history into the prompt every time | Grows linearly and burns tokens quickly |
| 2. Summary + recent (summarize old parts + keep the last N turns) |
Medium-to-long conversations, ~50 turns, want compression without losing too much | Every N turns, ask the LLM to summarize older history; prompt = summary + last N turns |
Moderate, with extra summarization cost |
| 3. Vector store + retrieval (external store + semantic search each turn) |
Cross-session interaction, knowledge-base scenarios, agents that need to "recall" distant information | Embed past messages → store them in a vector DB → retrieve relevant snippets per query and put them back into the prompt | High (vector compute + storage), but token usage stays stable |
How to choose:
- Conversational chatbots without cross-session needs → Pattern 1
- Agents with long conversations that need to remember what was discussed today → Pattern 2
- Agents with cross-session needs + a knowledge base (the common scenario in this stage's exercises) → Pattern 3
- Large production agents → usually a hybrid: recent history uses Pattern 1/2, long-term memory uses Pattern 3
💡 Track B focus: in Stage 7 multi-agent systems, each agent usually has "its own memory" + "shared memory". In practice that means a Pattern 2 + Pattern 3 hybrid. If you internalize these three patterns now, Stage 7 memory design becomes much easier.
⭐ 5 mainstream memory layers that can ship (choose by use case)¶
Star counts and benchmarks change. The point here is not ranking. The point is understanding the design orientation of each memory layer.
After learning the three patterns, you do not need to build a memory store from scratch in production. These five are all actively maintained Apache-2.0 / MIT options, each with a different strength:
| Framework | Stars | License | Primary use case | Key features |
|---|---|---|---|---|
| agentmemory | 7.7k★ | Apache-2.0 | Coding-agent cross-session memory | MCP-universal (Claude Code / Cursor / Gemini CLI / Codex / Hermes / OpenClaw), 95.2% R@5, 92% token saving, 51 MCP tools + 12 auto hooks, benchmark-driven |
| mem0 | 55.6k★ | Apache-2.0 | Chatbot / personal-assistant user-level memory | Auto fact extraction + forgetting + namespace, production-tested, largest community |
| Letta (formerly MemGPT) | 22.7k★ | Apache-2.0 | Long-session agents (measured in months) | OS-style paging memory (working + archival), persona stability, MemGPT paper lineage |
| Zep | 4.6k★ | Apache-2.0 | Temporal KG-based memory | Builds conversation history into a temporal KG for time-aware reasoning and audit trails |
| graphiti | 27.5k★ | Apache-2.0 | Real-time knowledge-graph agent memory | Turns an agent's past interactions into a time-aware knowledge graph it can look things up in; the engine behind Zep, usable on its own |
| LangMem | 1.4k★ | MIT | LangChain-native memory | Official LangChain memory library, integrates directly with LangGraph, useful when you are already committed to the LangChain stack |
How to choose: - Building coding agents → agentmemory (MCP-native, aligned with the Stage 5 ecosystem) - Building chatbots / personal assistants → mem0 (most mature, largest community) - Building long-running agents across weeks or months → Letta (strong OS-paging model) - Need time-aware reasoning + audit trails → Zep (temporal KG) - Already committed to the LangChain stack → LangMem (avoid framework hopping)
Additional official docs: Anthropic Memory Tool (Claude's official tool-based memory, file-based, direct API calls), LangChain Memory Concepts (comparisons of memory classes within the framework).
Advanced: CoALA Framework — A 4-Layer Taxonomy for Agent Memory¶
Sumers et al. 2023 — Cognitive Architectures for Language Agents categorizes agent memory into four types. This is one of the most useful mental models in practice:
| Type | What it stores | Corresponding example |
|---|---|---|
| Working memory | Current task context | The LLM context window itself |
| Episodic memory | Specific experiences from past tasks | Reflexion records, prior trajectories |
| Semantic memory | Abstract facts / knowledge | RAG knowledge bases, user profiles, preferences |
| Procedural memory | How to perform actions / skills | Tool definitions, Skills (Stage 5.3) |
→ Why it is useful: the three patterns above (buffer / summary / vector) mostly handle working + episodic memory. Production agents usually need to account for all four layers. CoALA is a practical checklist for spotting which layer your agent is missing.
Advanced: Generative Agents — Triple Score Weighting (Classic Case Study)¶
The Park et al. 2023 — Generative Agents: Smallville simulation featured 25 NPCs, each with its own memory stream. Retrieval used a weighted combination of three scores:
- Importance: LLM assigns a 1-10 importance score to each memory (eating = 2, breakup = 9).
- Recency: Exponential decay based on time.
- Relevance: Embedding similarity to the current query.
The final score = α·importance + β·recency + γ·relevance, ranked to retrieve top-k. This is the conceptual backbone used by many 2024-2025 production memory layer systems (mem0 / Letta).
💻 Official Code: joonspk-research/generative_agents ★ The paper's accompanying Smallville simulation code repository. Refer here for implementing memory streams and triple-score retrieval.
2024-2026 Latest Memory Works — 3 Main Themes¶
Memory research in 2024-2026 is focusing on 3 main themes:
- 🧠 Structured, Evolving, Associative Memory — Moving beyond flat vector stores to human-brain / Zettelkasten-inspired memory structures. Representatives: A-MEM (automatic linking between memories), HippoRAG 2 (KG + PageRank, hippocampus-inspired).
- 📚 Explosive Growth in 2026 Surveys — Five major surveys and cross-disciplinary syntheses in one year. Representatives: Memory in the Age of AI Agents (3D taxonomy + benchmarks), Memory for Autonomous LLM Agents (formalizing the write-manage-read loop).
- 🛡 Memory Security Emerges as a Subfield — As agents run longer, memory becomes vulnerable to cross-session poisoning / unauthorized access attacks. Representatives: Memory Security Survey (covered in Stage 7 Security).
4 Representative Works for Deep Dive:
| Work | One-Liner | Link |
|---|---|---|
| Anthropic Memory Tool | Claude's official tool-based memory, API calls, file-based | Anthropic Docs |
| A-MEM (Agentic Memory) | Zettelkasten-inspired, auto-links memories, evolving | Xu et al. 2025 ⭐ |
| HippoRAG 2 | KG + Personalized PageRank, cross-document multi-hop, ICML 2025 | Gutiérrez et al. 2025, OSU-NLP-Group/HippoRAG ⭐ |
| Memory in the Age of AI Agents (Survey) | 3D taxonomy (temporal / substrate / control) + benchmark compilation | Hu et al. 2025-12 ⭐ |
📚 Full Overview — 8 Other Memory Works Worth Knowing (Expand to View)
| Work | One-Liner | Year / Paper | |---|---|---| | **MemGPT → Letta GA** | OS-paging memory, working/archival layers, strong for long sessions | [Packer et al. 2023](https://arxiv.org/abs/2310.08560) → Letta GA | | **MemoryBank** | Ebbinghaus forgetting curve, accessed memories strengthened, unused ones decay | [Zhong et al. 2023](https://arxiv.org/abs/2305.10250) | | **MemoryLLM** | Self-updatable memory parameters embedded within the model weights, not context | [Wang et al. 2024](https://arxiv.org/abs/2402.04624) | | **mem0** (See 5 Mainstream Memory Layers) | A production memory layer with auto fact extraction + forgetting | [mem0ai/mem0](https://github.com/mem0ai/mem0) | | **Memory for Autonomous LLM Agents** (Survey) | Formalizes write-manage-read loop, covers 2022-2026 advancements | [arXiv:2603.07670](https://arxiv.org/abs/2603.07670) ⭐ 2026 | | **From Storage to Experience** (Survey) | Evolutionary framework: Storage → Reflection → Experience stages | [arXiv:2605.06716](https://arxiv.org/abs/2605.06716) ⭐ 2026 | | **ScrapMem** | Bio-inspired on-device memory, "Optical Forgetting" reduces resolution of old memories | [arXiv:2605.03804](https://arxiv.org/abs/2605.03804) ⭐ 2026-05 | | **Memory Security Survey** | Risks of cross-session poisoning, unauthorized access, and organizational propagation in long-term memory | [arXiv:2604.16548](https://arxiv.org/abs/2604.16548) ⭐ 2026 |🧩 Chunking Details (Technical Deep Dive)¶
Good chunking allows LLMs to generate more precise and complete answers within limited contexts. It's not just about splitting text evenly; it depends on the application scenario and document content. It determines the smallest semantic unit the retriever sees.
A good chunk should achieve two things: sufficient completeness for the model to understand context, and focused content to minimize retrieval noise. Chunks that are too small lose context, while chunks that are too large can dilute similarity search effectiveness.
Common Strategies:
- Fixed-Length: Splits based on character or token count. Simple and stable, but can cut sentences, paragraphs, or tables awkwardly.
- Sliding Window: Overlaps chunks to retain information at boundaries. Increases index size but reduces boundary information loss.
- Recursive: Tries to preserve paragraphs first; if still too long, falls back to sentences, then words. Often a good baseline for RAG entry-level.
- Semantic Chunking: Splits based on embedding similarity or semantic shifts, where similarity between consecutive chunks changes. Suitable for long documents but more complex and costly.
- Hybrid Strategies: Combines different methods based on document structure and application needs. For example, a research paper might need to preserve chapter context, tables, formulas, and citation references.
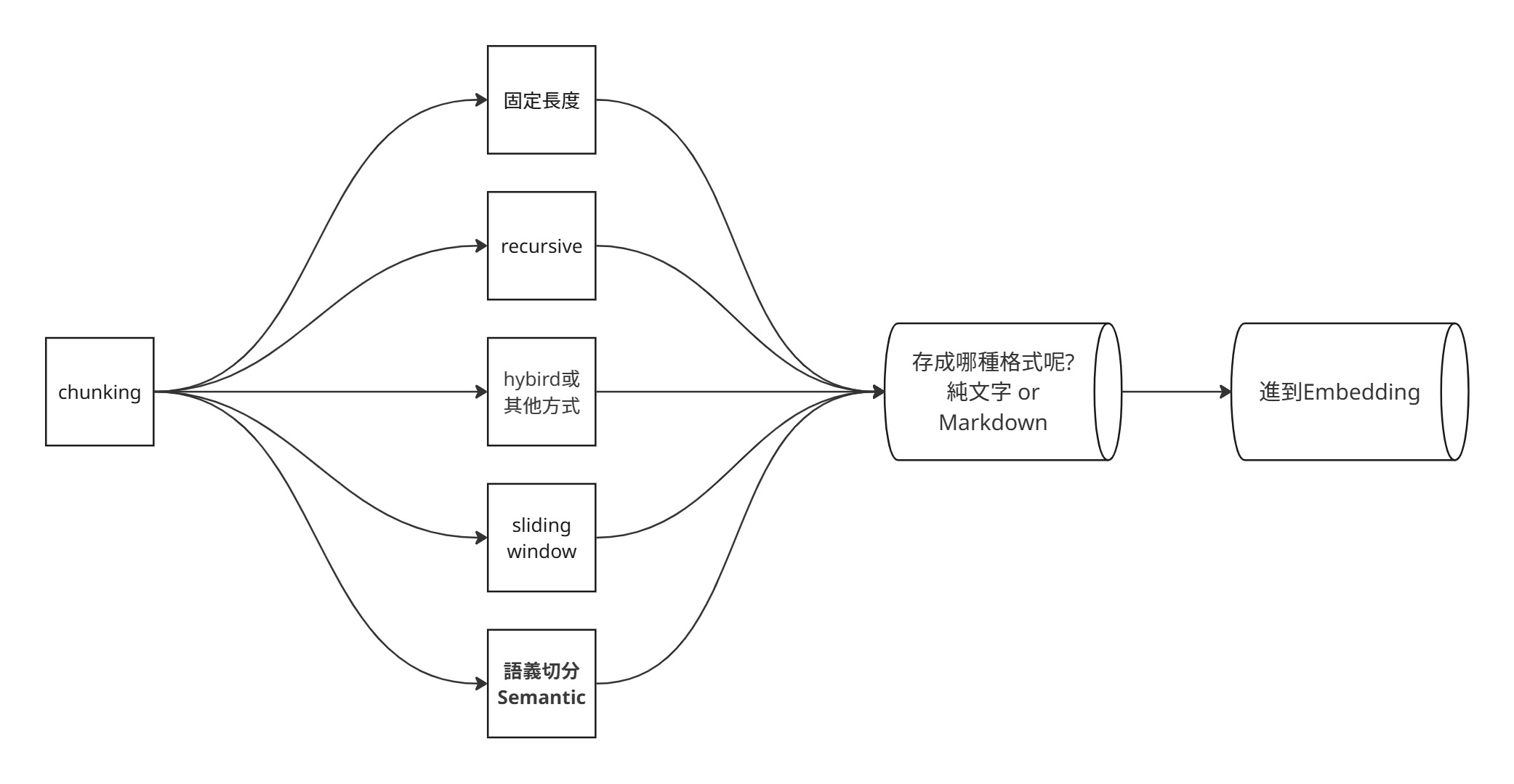
📚 Classic Tutorial: Greg Kamradt — 5 Levels of Text Splitting ★ Essential reading for chunking basics, covering everything from character-based to agentic chunking across five levels, including Jupyter notebooks.
For your first RAG implementation, avoid overly complex strategies. LangChain documentation recommends starting with RecursiveCharacterTextSplitter for most scenarios.
Run a baseline version first, then adjust chunking strategies based on retrieval results and failure cases.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text = "This is a very long document content... (omitting a thousand words here)..."
splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20,
length_function=len,
)
chunks = splitter.split_text(text)
print(f"Split into {len(chunks)} chunks")
print(chunks[0])
Intuitive Assessment of Chunking Quality:
- Answers missing information or are incomplete: Usually due to small chunks or insufficient overlap.
- Answers contain correct information but also irrelevant details: Usually due to large chunks or too many retrieved items (high top-k).
Advanced Considerations:
- Chunking is not a one-time setup; it requires iterative refinement based on real queries and failure cases.
- Chunk size, overlap, top-k, and reranker interact; don't adjust one parameter in isolation.
- Consider how you would chunk PDFs with images, meeting transcripts with timestamps, or structured data like tables.
- Advanced chunking variations (Sentence-Window / Parent-Child / Multi-Vector) are covered in the Overview of Advanced RAG Techniques table.
🪞 Advanced: Full Reflexion with Persistent Memory ⭐ Track B Elective¶
This section covers concepts and routing; it's not a practice exercise. It expands on the basic Reflexion from Stage 3 Reflection by explaining why some reflections require persistent memory—this version truly belongs in Stage 6.
Difference Between Full Reflexion and Self-Refine:
| Version | Retains within Session | Retains Across Sessions | Memory Pattern Required |
|---|---|---|---|
| Self-Refine (Madaan 2023) | Previous round's answer + critic feedback | ❌ Not retained | None required (Pattern 1 buffer is sufficient) |
| Full Reflexion (Shinn 2023) | Same as above | ✅ Stores "reflection summaries" from past trials into episodic memory, retrieved into prompts for future similar tasks | Required (Pattern 3 vector store or Pattern 2 summary) |
Why This Version Requires Memory: The core of Reflexion's verbal reinforcement learning is "agent accumulates lessons across trials"—the agent attempts a task, fails, reflects on "why it failed" and stores it, then retrieves past reflections when encountering similar tasks to avoid repeating mistakes. This requires persistent episodic memory, directly connecting to the 3 memory patterns discussed earlier in this stage.
Typical Architecture (Full Persistent Memory Version):
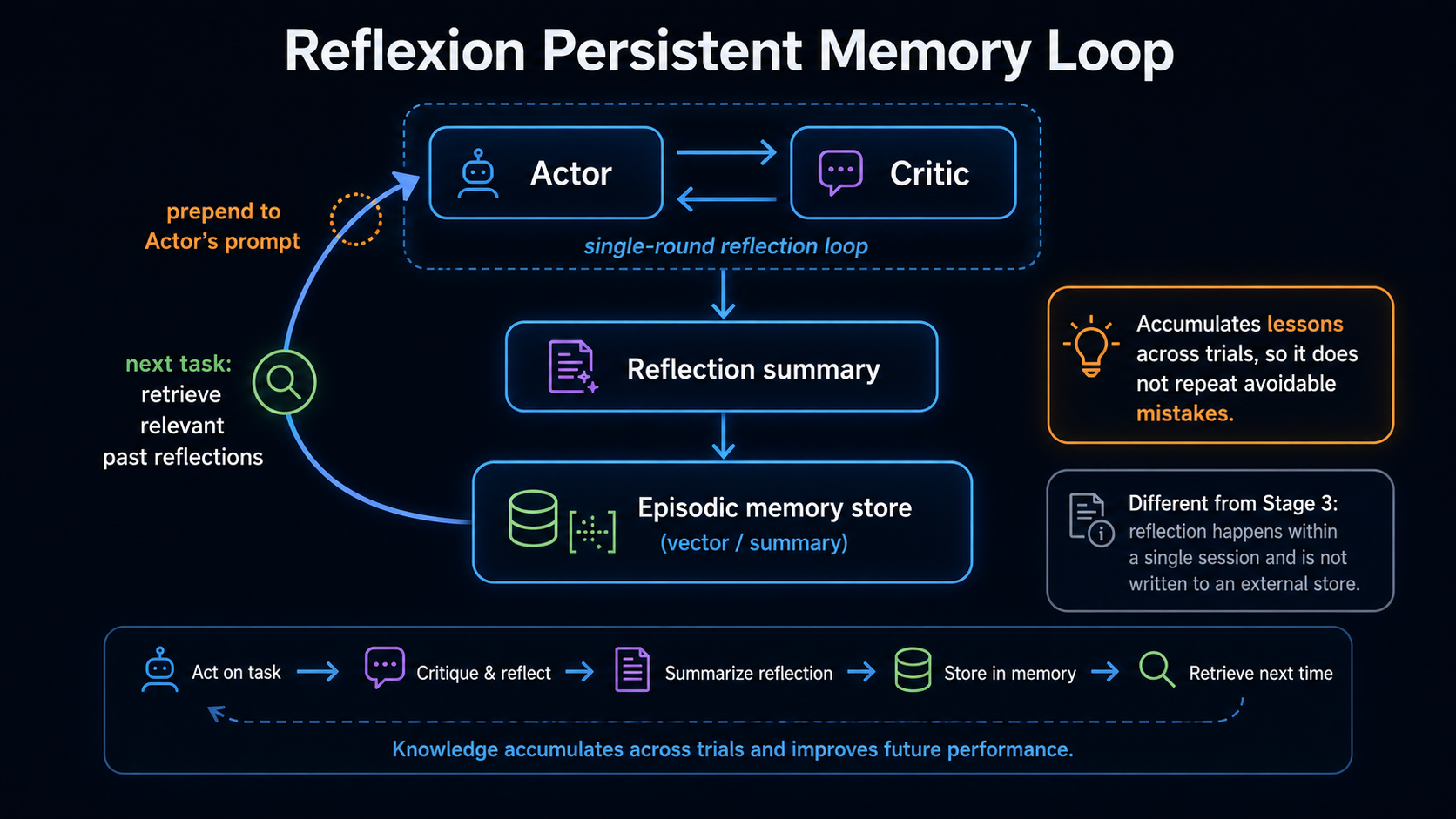
→ Difference from Stage 3 Reflection: Stage 3 focuses on an in-context loop within a single session (no external store). This section covers persistent episodic memory storage + retrieval across trials to learn from past experiences.
📚 Want to Implement / Dive Deeper¶
Papers: - Reflexion (Shinn et al. 2023) ⭐ — The full version paper. Algorithm 1 outlines how the memory buffer is used. - Self-Refine (Madaan et al. 2023) — Baseline comparison; version without episodic memory.
Reference Implementations: - noahshinn/reflexion — Reference implementation by the paper's lead author (includes full episodic memory workflow). - LangChain — Reflexion — LangGraph version, directly integrable with the RAG pipeline exercise in this stage. - mem0 (listed above) + Letta (listed above) — Memory layers that can directly serve as episodic stores for Reflexion.
💡 Delineation with Stage 3 Reflection: - To understand "how the reflection loop works and runs in a single turn" → Stage 3 Reflection. - To understand "how reflections accumulate across sessions and agents learn from past lessons" → This section. - To see how reflection is used in production agents (Cursor / Claude Code) → Stage 5 5.7 Harness Internals.
🤔 Advanced Reasoning / Reflection — 2024-2026 Trends ⭐ Covers Both Tracks¶
Reflexion is prompt-based reflection—LLMs modify themselves during inference. 2024-2025 saw the emergence of a second path: training reflection into the model weights (OpenAI o1 / DeepSeek R1). You should be aware of both approaches.
Path 1: Prompt-Based Reflection / Reasoning (Traditional Approach)¶
| Technique | Core Idea | Paper |
|---|---|---|
| Self-Consistency | Sample N reasoning paths, take majority vote — Simplest & Most Common | Wang et al. 2022 |
| Tree of Thoughts (ToT) | Reasoning becomes a tree, allowing branching and backtracking; suitable for puzzles / planning. | Yao et al. 2023 |
| Graph of Thoughts (GoT) | Extends ToT beyond trees to arbitrary graph structures. | Besta et al. 2023 |
| Chain-of-Verification (CoVe) | Generate an answer → Ask verification questions to itself → Correct the answer. | Dhuliawala et al. 2023 |
| CRITIC | Tool-augmented self-critique (using search / calculator for verification). | Gou et al. 2023 |
| Self-Discover | Agent first "discovers" the reasoning structure to use before executing. | Zhou et al. ICML 2024 ⭐ 2024 |
| Self-Refine / Reflexion | Covered above / in Stage 3. | Stage 3 Reflection, this stage Reflexion |
Path 2: Trained-in Reasoning / Reflection (Major Shift in 2024-2026)¶
📺 Visual Learning: Hung-Yi Lee 2025 Lecture 7 — How Large Language Models Like DeepSeek-R1 Perform "Deep Thinking" (Reasoning) (NTU Machine Learning in the Era of Generative AI 2025)
OpenAI's o1 (Sep 2024), followed by open-source efforts like DeepSeek's R1 (Jan 2025), DeepSeek-V4-Pro (Apr 2026 preview, agent-focused open-source reasoning), Claude Fable 5 (Jun 2026, Mythos-class, above the Opus class; access suspended 2026-06-12, currently unavailable), Claude Opus 4.8 (May 2026, Opus-class flagship and current top usable tier, Dynamic Workflows + parallel subagents), GPT-5.5 (Apr 2026), and Gemini 3.1 Pro (Feb 2026) represent the current frontier, with GPT-5.6 (Sol / Terra / Luna, limited preview) and Gemini 3.5 Flash arriving late Jun 2026. These models have "step-by-step thinking + self-correction" trained directly into their weights, automatically unfolding long reasoning chains (thinking tokens) during inference. This is the biggest paradigm shift in LLMs from 2024-2026, with all frontier models adopting this approach. The table below lists current (Jun 2026) frontiers—historical predecessors (o1 / R1 / Sonnet 4.5 / Gemini 2.5) are omitted; refer to release dates for lineage.
| Model | Source / Release | Features | Link |
|---|---|---|---|
| GPT-5.5 | OpenAI 2026-04 (Predecessors: o1 2024-09 → o3 → GPT-5 2025-08 → 5.4 2026-03) | Closed-source, unified reasoning + chat, Thinking budget API, enhanced agent capabilities. Newer tier: GPT-5.6 (Sol / Terra / Luna), limited preview Jun 2026 | OpenAI |
| Claude Fable 5 | Anthropic 2026-06 (Mythos-class, positioned above the Opus class; released alongside Claude Mythos 5, a limited-availability variant with some safeguards lifted) | Closed-source, Mythos-class (above the Opus class). ⚠️ Access suspended 2026-06-12 by a US export-control directive (status); Fable 5 and Mythos 5 are currently unavailable with no restoration timeline; use Opus 4.8. Official benchmark numbers were never published | Claude Fable 5 / Mythos 5 |
| Claude Opus 4.8 | Anthropic 2026-05 (Predecessors: Sonnet 4.5 / Opus 4.5 / Opus 4.7; Dynamic Workflows research preview) | Closed-source, Opus-class flagship and current top usable Claude tier (was Fable 5's safeguard fallback; Fable 5 suspended 2026-06-12), controllable thinking budget (API parameter), leading in SWE-bench / Terminal-bench | Anthropic extended thinking |
| Gemini 3.1 Pro | Google 2026-02 (Predecessors: Gemini 2.5 Thinking 2025, Gemini 3 2025-11) | Closed-source, viewable thinking traces, GPQA Diamond 94.3%, leading in price/speed/multimodality. Newer tier: Gemini 3.5 Flash, available Jun 2026 (3.5 Pro in dev) | Gemini API |
| DeepSeek-V4 / V4-Pro / V4-Flash | DeepSeek 2026-04 preview (Predecessors: R1 2025-01 → V3.1) | Open-source MIT license, agent-focused training, integrated reasoning + tool use + knowledge processing. R series reasoning now mainline. | HF DeepSeek-V4-Pro, R1 paper (method baseline), CNBC report |
| QwQ-32B / QvQ-72B | Alibaba Qwen 2024-11 ~ 2026 | Open-source Apache 2.0, QwQ-32B remains a strong option for small-size reasoning, QvQ is the visual variant. | QwQ blog |
How to Choose Between the Two Paths¶
| Your Situation | Recommendation |
|---|---|
| Using a general chat model base and want to add reasoning | Path 1 (Prompt-based) — ToT / Self-Consistency / CoVe |
| Budget/latency allows for strongest reasoning | Path 2 — Choose among GPT-5.5 / Opus 4.8 / Gemini 3.5 Flash / Grok 4.3 / V4-Pro (Claude Fable 5 suspended as of 2026-06-12) |
| Want to fine-tune your own reasoning model | Path 2 — Study the R1 paper (method baseline), start from R1-Distill / V4 open-source weights |
| On-device / Extremely tight budget | QwQ-32B (Apache 2.0) or R series distilled versions |
| Multi-agent debate / critic scenarios | Path 1 (CRITIC / debate) + Stage 7 Multi-agent |
💡 2025-2026 Trends: - Reasoning models are integrating Reflexion's capabilities into their weights—however, prompt-based reflection is not obsolete. Agent loops (controlling reflection timing/content) and multi-agent debates remain essential. - Open-source is rapidly catching up to closed-source. DeepSeek-V4-Pro (Apr 2026 preview, MIT license) integrates R1 reasoning into its mainline, trained with an agent-first approach, narrowing the gap with GPT-5.5 / Gemini 3.5 Flash. - Agent capabilities are becoming the primary selling point. V4 / Opus 4.8 position agents-as-products (SWE-bench / Terminal-bench / tool use) as headline benchmarks, moving beyond just raw reasoning. - Both paths will coexist; production agents will likely leverage both.
📏 RAG / Memory Eval — Running is Not Running Accurately¶
Why This Section is Crucial: The biggest pitfall in RAG/Memory systems is "they seem to run, but retrieval accuracy is poor." Without evaluation, you won't know if changing chunk size, embedding model, or adding a reranker actually helps—you'll only have subjective impressions like "the answer seems smoother." Production agents without evaluation are essentially untested.
3 Core Metrics:
| Metric | Measures What | Tools |
|---|---|---|
| Retrieval Recall@K | Whether the ground truth answer's chunk is within the top-K retrieved chunks. | ragas / TruLens / LangSmith |
| Answer Faithfulness | Whether the generated answer is grounded in the retrieved chunks (vs. model hallucination). | ragas / TruLens |
| Answer Relevance | How relevant the answer is to the query (avoids off-topic responses). | ragas / LLM-as-judge |
Representative Frameworks:
- explodinggradients/ragas ★ 13.9k Apache-2.0 ⭐ — The standard tool for RAG evaluation, including 8+ metrics (faithfulness, answer relevance, context precision, context recall, etc.), supporting both reference-free and reference-based evaluation.
- TruLens — Integrates observability and evaluation, with good LangChain / LlamaIndex support.
- LangSmith — LangChain's official evaluation + tracing platform (closed-source SaaS).
How to Start: After completing Exercise 4 (Full RAG Pipeline), integrate RAGAS evaluation to measure a baseline. Then, adjust chunking/embedding/top-k and observe how the metrics change. Without this step, parameter tuning is just guesswork.
→ Stage 7 Evaluation builds upon this section, extending evaluation to multi-agent systems / full harnesses.
🛠 Hands-on Exercises (Illustrative Basics)¶
Exercise 1: Embeddings¶
Embed 100 sentences, find nearest neighbors for a query. Understand the meaning of vector distances.
Exercise 2: Vector DB¶
Store embeddings in Chroma, perform semantic queries. Compare the results against keyword search.
Exercise 3: Chunking Comparison¶
Use three chunking methods on the same document: fixed length, paragraph-based, heading-aware. Compare top-k results for 5 real questions, noting which method retrieves the correct context more easily.
Exercise 4: Full RAG Pipeline¶
Chunk a PDF → Embed → Retrieve top-k → Generate an answer. This is the basic skeleton for most RAG applications.
Exercise 5: Long-term Memory¶
Enable an agent to remember things across multiple conversation turns. Use mem0 or build your own with a vector store.
🛠 Recommended Tools for Common Memory / RAG Use Cases (Categorized by Purpose)¶
Unsure where to start with tool selection? Here are commonly used combinations in the industry post-2025—choose based on your scenario ("Entry Point") and follow the links for deeper dives:
| Scenario | Recommended Tools | Why |
|---|---|---|
| First RAG Implementation (Quickest Start) | Chroma + LlamaIndex | Local-first, zero-ops, beginner-friendly quickstart. Default for Stage 6 exercises. |
| Enterprise-Grade RAG Framework (Alternative to LangChain/LlamaIndex) | Haystack (deepset) ★ 25.2k Apache-2.0 | Open-source by deepset, production-oriented orchestration, mature for enterprise NLP scenarios. |
| Agent Long-Term Memory (See 5 mainstream memory layers that can ship) | agentmemory / mem0 / Letta / Zep / LangMem | Detailed above in 5 mainstream memory layers that can ship. |
| RAG / Memory Evaluation (Must-Have) | ragas ★ 13.9k | Standard RAG evaluation tool, 8+ metrics, reference-free + reference-based. |
| Production-Scale RAG (Millions of Docs) | Qdrant + LlamaIndex | Rust-based vector DB, faster than Chroma at scale. |
| Existing Postgres Environment | pgvector | Postgres extension, unified SQL + vector in one DB, simplest ops. |
| Enterprise RAG + Web UI | RAGFlow | Robust document parsing (OCR/tables/layout), enterprise-grade, includes Web UI. |
| Chinese RAG Template | Langchain-Chatchat | Widely used in Chinese community, local LLM integration (ChatGLM/Qwen/Llama), good Chinese defaults. ★ 38k+, Apache-2.0. ⚠️ Last update Nov 2025 (marginal). |
| Advanced: Contextual Retrieval | Anthropic Cookbook | Claude with prompt caching for contextual chunking (See Advanced RAG Techniques). |
| Advanced: Knowledge Graph Reasoning | LightRAG / Microsoft GraphRAG | Knowledge graph + RAG, entity-relation reasoning (See Advanced RAG Techniques). |
| Tutorial Collection | ai-engineering-hub | RAG + agent tutorial collection, Jupyter notebook format. |
Recommended Entry Sequence: 1. First essential installation: Chroma + LlamaIndex (for Stage 6 exercises). 2. For agent memory needs: Add mem0 (simplest memory layer). 3. For production scaling: Switch to Qdrant or pgvector. 4. For upgrading to advanced RAG: Explore techniques in the Advanced RAG Techniques section.
🎯 Featured Projects (Templates / Specs / Example Collections)¶
Categorized for quick reference; choose by use case ("Entry Point") and follow the links for deeper dives.
| Category | Project | ⭐ | Who It's For | Why Recommended / Notes |
|---|---|---|---|---|
| RAG Framework (Full Pipeline) |
LlamaIndex | ⭐⭐⭐⭐⭐ | Applications focused on documents | Core RAG library, provides document loaders / chunking / retrieval / query engines. ★ 49k+ |
| infiniflow/ragflow | ⭐⭐⭐⭐⭐ | Teams shipping RAG to non-developers | Production-ready RAG engine, deep document understanding (layout/tables/OCR) + hybrid retrieval + agent loops + Web UI. ★ 79k+, Apache-2.0. | |
| HKUDS/LightRAG | ⭐⭐⭐⭐ | Those exploring research-grade graph + long-context memory methods | Graph + vector hybrid retrieval + summarization-based memory, backed by EMNLP 2025 paper. ★ 34k+, MIT. Research-oriented codebase. | |
| Vector DB (Local-First) |
Chroma | ⭐⭐⭐⭐⭐ | Exercises 2 / 4, easiest vector DB to start with | Open-source embedding database, runs locally, in-memory/SQLite backend, zero ops. ★ 27k+, Apache-2.0. Install: pip install chromadb |
| Vector DB (Production Scale) |
Qdrant | ⭐⭐⭐⭐⭐ | When Chroma can't keep up, need production scale | Rust-based vector DB, offers cloud and self-hosted options. ★ 31k+ |
| Vector DB (Hybrid) |
Weaviate | ⭐⭐⭐⭐ | Production deployment + schema constraints | Built-in modules (text2vec/generative/classification), schema-driven, native BM25 + vector hybrid. ★ 16k+ |
| Vector DB (Existing Postgres) |
pgvector | ⭐⭐⭐⭐ | Teams already using Postgres | Postgres extension, unified SQL + vector in one DB, simplest ops. ★ 21k+ |
| Vector DB (Runs in-app) |
lancedb/lancedb | ⭐⭐⭐⭐ | Apps that want a vector DB built in, with no separate server | A vector DB that runs inside your app (no server to start); handles text + images, and searches by keyword + vector together. ★ 10k+, Apache-2.0. |
| Memory Framework (Auto Fact Extraction) |
mem0ai/mem0 | ⭐⭐⭐⭐⭐ | Personal assistants / chatbots needing user-level memory | Self-refining memory layer, cross-session fact storage. ★ 59k+ |
| Memory Framework (OS-Paging) |
Letta (formerly MemGPT) | ⭐⭐⭐⭐ | Agents running for extended periods (months) | Hierarchical memory (working/archival), OS-paging concept. ★ 22k+ |
| Memory (In-Framework) | LangChain — Memory | ⭐⭐⭐ | Already using LangChain | 4 abstract memory types (buffer/summary/vectorstore-backed/entity). |
| Advanced RAG Techniques | Anthropic — Contextual Retrieval Cookbook | ⭐⭐⭐⭐⭐ | After basic RAG, want to upgrade | Claude with prompt caching for contextual chunking (full end-to-end examples). |
| Chinese RAG Template | chatchat-space/Langchain-Chatchat | ⭐⭐⭐⭐ | Chinese knowledge bases / RAG applications | Widely used in Chinese community, local LLM support (ChatGLM/Qwen/Llama/Ollama), good Chinese defaults. ★ 38k+, Apache-2.0. ⚠️ Last update Nov 2025 (marginal). |
| Tutorial Collection | ai-engineering-hub | ⭐⭐⭐⭐ | Interested in seeing "how the same concept is implemented in different contexts" | Thematic LLM / RAG / agent tutorial collection, Jupyter notebooks, useful across many stages. ★ 34k+, MIT. |
| Production AI Assistant (Learn to Ship RAG) |
onyx (formerly Danswer) | ⭐⭐⭐⭐⭐ | Want to see "how RAG-driven AI assistants are productionized" | Open-source enterprise AI assistant, cross-LLM support, full ingest/retrieval/chat/admin. ★ 29.4k, active maintenance. |
| RAG Cookbook (30+ Techniques) |
NirDiamant/RAG_Techniques | ⭐⭐⭐⭐⭐ | After basic RAG, want to explore various implementations | Large RAG techniques cookbook, includes Self-RAG / HyDE / Multi-Query / Adaptive and 30+ Jupyter notebook examples. |
| DSPy (Programming not Prompting) |
stanfordnlp/dspy | ⭐⭐⭐⭐⭐ | Used LLMs for a while, want to auto-optimize prompts + chains | Stanford NLP group, ★ 34.4k MIT, Path 3 paradigm (See DSPy in Advanced RAG Techniques) |
| RAG / Memory Eval (Must-Have) |
explodinggradients/ragas | ⭐⭐⭐⭐⭐ | After completing Exercise 4 (Full RAG Pipeline), want to measure retrieval accuracy | Standard RAG evaluation tool, 8+ metrics, reference-free + reference-based. ★ 13.9k Apache-2.0 |
✅ Self-Check Before Entering Stage 7¶
Can you:
- Write a 50-line RAG pipeline (load → chunk → embed → store → query → answer)?
- Explain why naive chunking fails on long documents?
- Design different chunking strategies for API docs, PDFs, and tables?
- Choose between Chroma, Qdrant, and pgvector based on scale?
- Differentiate between "giving an agent memory" and "using RAG"?
- Explain where RAG and Memory complement each other (refer to the table in From RAG to Memory)?
If yes → Proceed to Stage 7 — Multi-Agent · Productionization.