Exercise 1: Multi-Agent Debate¶
Pairs with Stage 7 — Multi-Agent & Production Exercise 1.
Task¶
Three agents (PRO + CON + Judge) debate the same question:
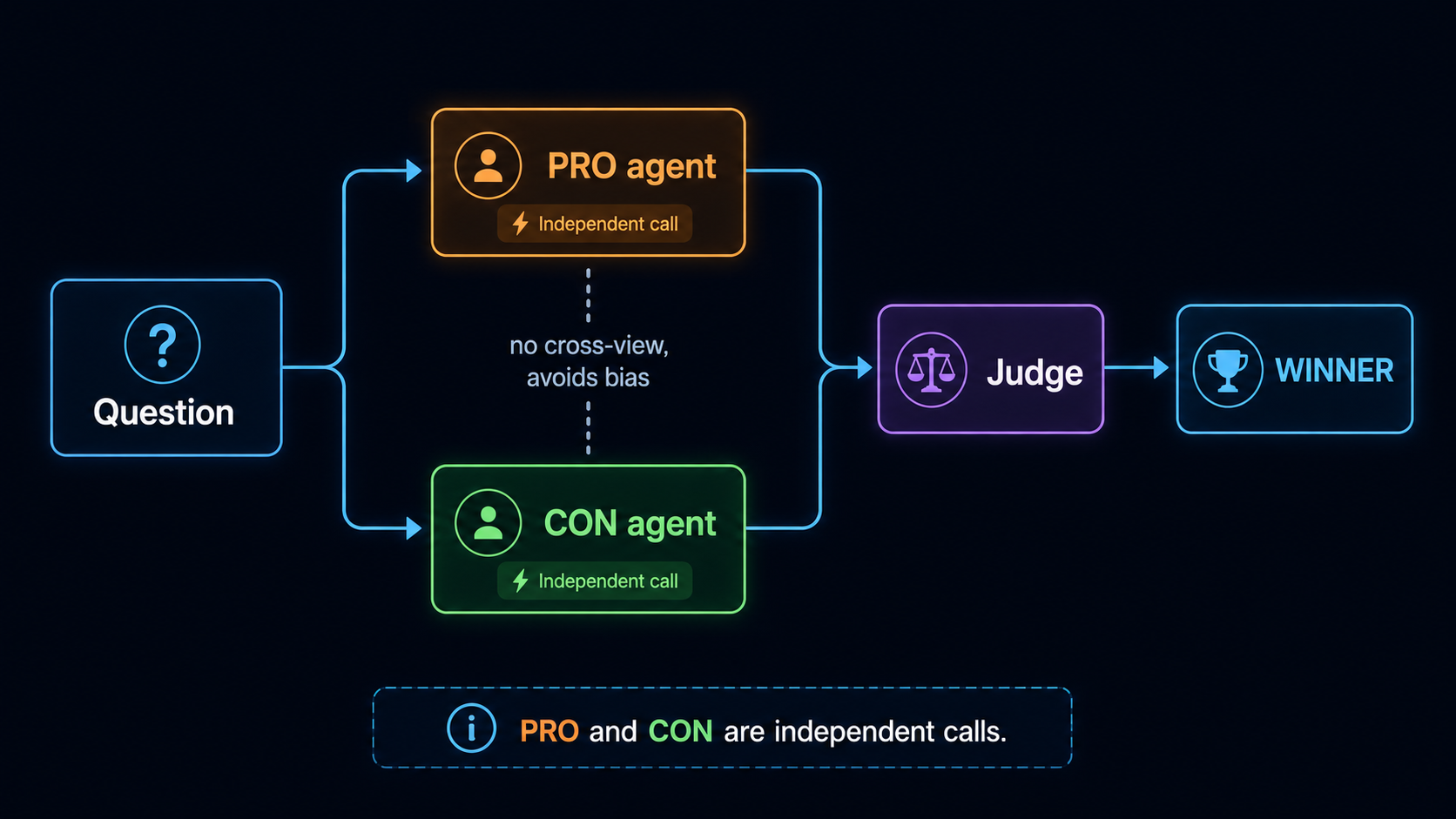
PRO and CON are called independently — they don't see each other's arguments (prevents bias propagation). The Judge sees both and decides.
Why this pattern matters¶
- Reduces single-LLM bias: one LLM tends to bake in a stance and ignore counterarguments
- Strengthens reasoning: forcing both sides to articulate produces cleaner traces
- Auditability: high-stakes production decisions (policy / medical / legal review) need trails
- Disagreement = signal: when agents disagree, the question may be ambiguous or the model uncertain
How to run¶
Path A (default, free, local)¶
pip install -r requirements.txt
ollama pull qwen2.5:3b
ollama serve
python starter.py
Budget: $0. Three LLM calls × CPU ≈ 15-45s.
Path B (Anthropic)¶
pip install -r requirements.txt
export ANTHROPIC_API_KEY=sk-ant-...
python starter_anthropic.py
Budget: ~$0.003 per run (3 calls × short prompts × claude-haiku-4-5).
Validate the logic¶
python test.py # 3 tests with mock LLM, verify judge sees pro+con
python test_anthropic.py
Key design points¶
# Same model, different system prompts
pro = llm_call(system="argue PRO position", user=question)
con = llm_call(system="argue CON position", user=question)
# Judge sees question + pro + con
judge = llm_call(
system="neutral judge, output WINNER=PRO or WINNER=CON",
user=f"Question: {question}\n\nPRO: {pro}\n\nCON: {con}",
)
Key: PRO and CON are independent calls. Don't pass PRO's output into CON — CON would then react to PRO rather than think independently, amplifying bias.
Production-ready variants¶
- N-way debate: 3+ agents holding different perspectives (e.g., "engineer / PM / customer view")
- Iterative debate: PRO and CON see each other and rebut for N rounds; first to concede loses
- Different models: PRO uses Claude, CON uses GPT, Judge uses Gemini — cross-model debate finds blind spots
- Self-consistency: run the debate 3 times, see how stable the Judge's verdict is
Path observations¶
| Observation | Anthropic Claude | Ollama qwen2.5:3b |
|---|---|---|
| PRO / CON hold their positions | Stable | Sometimes both turn "balanced" — no clear stance |
| Judge outputs clear WINNER | Stable | Occasionally skips the WINNER= format |
| Reasoning quality | High | Medium |
| Cost | $0.003 | $0 |
Common pitfalls¶
- Identical system prompt for PRO and CON: outputs converge, debate is meaningless
- Fixed PRO-then-CON order in Judge prompt: may bias toward whichever comes first (recency / primacy). Production should shuffle
- No structured Judge output: without
WINNER=PRO or CONformat, downstream parsing is painful - Prompts too short: 1-sentence PRO and CON give the Judge nothing to weigh