练习 1:Multi-Agent 辩论¶
对应 Stage 7 — Multi-Agent & Production 练习 1。
任务¶
3 个 agent(PRO + CON + Judge)对同问题辩论:
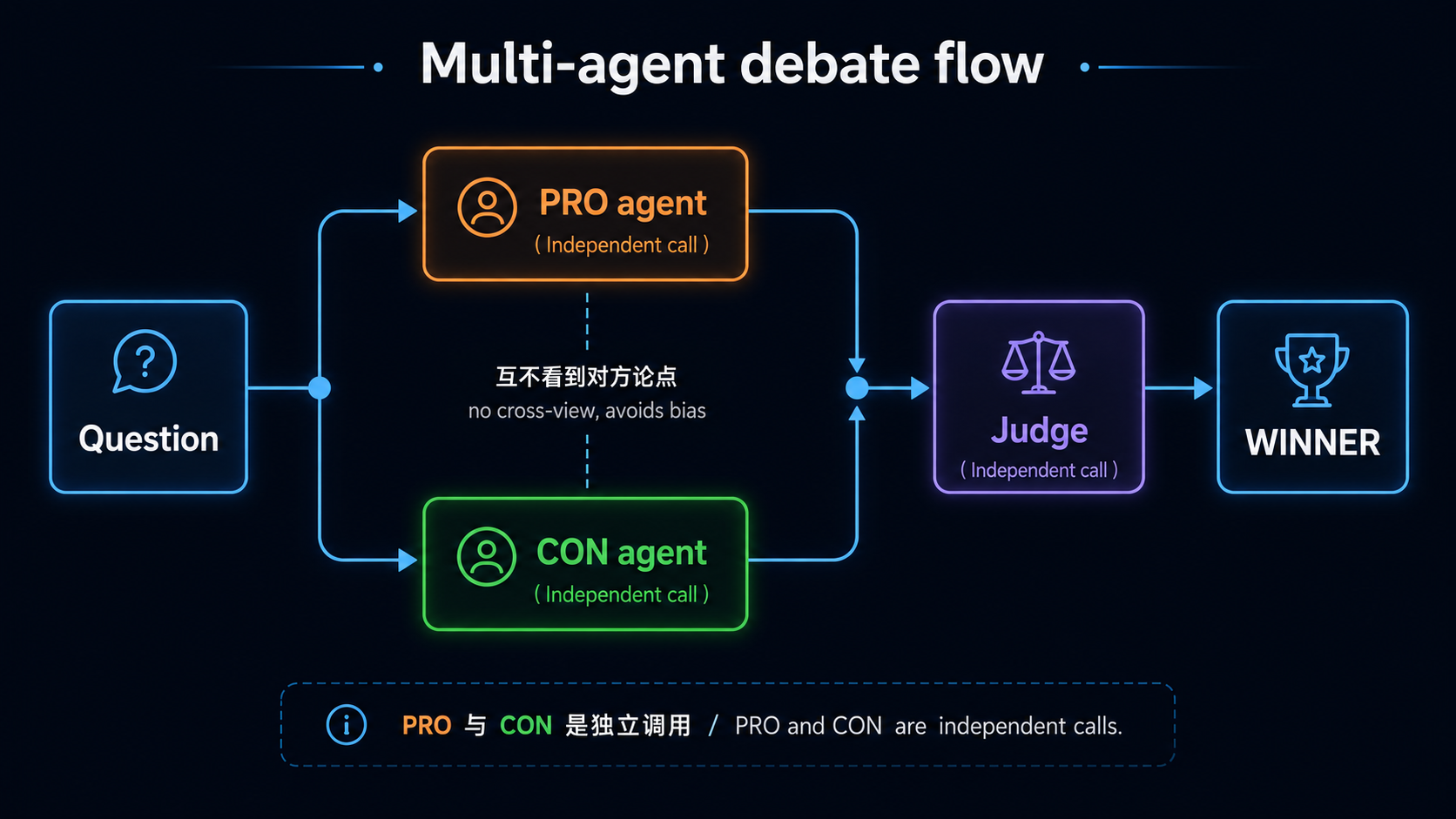
PRO 跟 CON 独立 call、互不看到对方论点(避免 bias propagation);Judge 看完两边再裁决。
为什么这个 pattern 重要¶
- 降低 single-LLM bias:单一 LLM 给的答案常带 stance、不主动指出反面
- 强化 reasoning:两个 LLM 强迫 articulate 各自立场、reasoning trace 更清楚
- 可解释性:production 高风险决策(policy / 医疗 / 法律 review)有 audit trail
- 错误侦测:两 agent 互不同意时、可能就是答案有歧义 / model 不确定
怎么跑¶
Path A(默认、本机免费)¶
pip install -r requirements.txt
ollama pull qwen2.5:3b
ollama serve
python starter.py
预算:$0。3 个 LLM call × CPU ≈ 15-45 秒。
Path B(Anthropic)¶
pip install -r requirements.txt
export ANTHROPIC_API_KEY=sk-ant-...
python starter_anthropic.py
预算:每次 ≈ $0.003(3 LLM call × short prompt × claude-haiku-4-5)。
不花钱验证程序逻辑¶
python test.py # 3 个 test、mock 3 LLM call、验 judge 看到 pro+con
python test_anthropic.py
重要设计细节¶
# pro / con 用同一个 model、不同 system prompt
pro = llm_call(system="argue PRO position", user=question)
con = llm_call(system="argue CON position", user=question)
# judge 看「question + pro + con」做裁决
judge = llm_call(
system="neutral judge, output WINNER=PRO or WINNER=CON",
user=f"Question: {question}\n\nPRO: {pro}\n\nCON: {con}",
)
Key:pro / con 独立 call——不要把 pro 结果丢给 con。如果 con 看到 pro、会倾向反驳 pro 而非独立思考、bias 反而加强。
Production-ready 变形¶
- N-way debate:3+ agent 各持不同立场(e.g. "engineer / PM / customer view")
- Iterative debate:pro 跟 con 互看 N 轮、看谁先放弃
- Different models:pro 用 Claude、con 用 GPT、judge 用 Gemini——cross-model debate 找盲点
- Self-consistency check:跑 3 次 debate、看 judge 结果稳定度
两个 path 观察重点¶
| 观察项 | Anthropic Claude | Ollama qwen2.5:3b |
|---|---|---|
| pro / con 持立场 | 稳 | 偶尔两边都讲“平衡 view”、立场不坚定 |
| judge 给明确 WINNER | 稳 | 偶尔不给 WINNER= 格式 |
| reasoning 质量 | 高 | 中 |
| 成本 | $0.003 | $0 |
常见坑¶
- PRO 跟 CON 用同一个 system prompt:模型答案会同质、debate 意义消失
- Judge 看 pro/con 顺序固定:可能 bias 第一个(recency / primacy effect)。production 可以随机 shuffle
- 没 structured judge output:不写
WINNER=PRO or CON格式、后续 parsing 困难 - 太短 prompt:pro / con 各只给 1 句、judge 没材料