5 Agent Paradigms — Where does your agent live, and who does it serve?¶
📌 This is a mental-model reference. After reading you'll understand: "Why do Claude Code, Hermes Agent, and OpenClaw all call themselves 'agents' but feel completely different to use?" If you already know which one you want →
resources/cli-agents-guide.en.md(7-CLI side-by-side comparison) orresources/cookbook.en.md(step-by-step deployment).
The word "agent" gets used loosely. Cursor is an agent. Claude Code is an agent. Hermes Agent — the one chatting with you on Telegram — is an agent. OpenClaw running on a Jetson board in your apartment is also an agent. But these four feel completely different in practice — because they belong to different paradigms. The difference isn't which LLM family they use; it's where the agent runs, what interface you use to talk to it, and whether it needs an internet connection.
Once you understand the paradigm, moving a use case from Type 2 to Type 4 isn't "switching tools" — it's switching how you think.
One table to anchor everything¶
| Type | Examples | Where the agent runs | How you reach it | LLM | Offline OK? | Monthly cost (rough) |
|---|---|---|---|---|---|---|
| 1. IDE-coupled | Cursor / Cline / Continue | Inside your IDE | IDE sidebar | Multi-provider | ❌ | $0-20 |
| 2. Terminal pair-programmer | Claude Code / Codex / Gemini CLI | Your terminal | Terminal REPL | Single-family | ❌ | $20 sub or API |
| 3. BYO-LLM CLI | Aider / OpenCode / goose | Your terminal | Terminal REPL | Bring your own API key | ❌ | API usage |
| 4. Cloud-deployed | Hermes Agent | $5 VPS / Modal | Telegram / Slack / any chat app | 200+ provider routing | ❌ | $5 server + API |
| 5. Edge-deployed | OpenClaw / ClawBox | Jetson board / Raspberry Pi | local chat / SSH | Local Ollama (Qwen / Llama / Mistral) | ✅ | One-time €549, then 0 |
→ Types 4 and 5 are both "deployed autonomous agents" — the agent doesn't live on your laptop, it runs out there 24×7 serving you. Type 4 lives in the cloud; Type 5 lives on edge hardware. Types 1-3 are "co-located agents" — the agent shares your laptop and stops when you walk away.
Type 1: IDE-coupled — "sidebar pair-programmer"¶
Examples: Cursor / Windsurf / Cline / Continue / Zed
Hero example:
You're writing a React component in Cursor. Editor on the left, Cursor sidebar on the right. You select a chunk of code, hit Cmd+K, and Cursor rewrites it in place. You see the inline diff and accept/reject.
Why this type exists: When you write code, your eyes need to be on the code — you can't pivot to a separate terminal for chat. IDE-coupled agents keep the LLM next to your sightline, preserving visual context.
Good for: lots of small edits, less exploration; side-by-side coding; visual diffs. Not for: agent autonomously running multi-step tasks (a sidebar isn't a great workspace); non-coding tasks.
Type 2: Terminal pair-programmer — "the Claude Code paradigm"¶
Examples: Claude Code / Codex / Gemini CLI
Hero example: You open Claude Code in a terminal and type "refactor the entire auth module, swap callbacks for async/await, run the tests." Claude Code reads files, edits them, runs pytest, and reports back. Five to ten minutes of streaming output, autonomous throughout.
Why this type exists: Claude Code and Codex turn the whole terminal into the agent's workspace. The agent has full access to the file system, shell, and git — it can complete multi-step tasks autonomously. More autonomous than Type 1.
Distinguishing trait: Subscription pricing ($20/month covers the whole month, no per-token billing); locked to a specific LLM family (Claude Code = Claude only).
Good for: agentic tasks; long refactors; paper writing; anything beyond a 1-2 step prompt. Not for: cost-comparing across LLM providers; non-coding/writing scenarios; offline work.
Type 3: BYO-LLM CLI — "Type 2's mental model, multi-provider"¶
Examples: Aider / OpenCode / goose / Hermes Agent*
Hero example:
You want to use DeepSeek-R1 to write code (10× cheaper than Claude Opus). Aider with --model deepseek/deepseek-reasoner + an OPENROUTER_API_KEY does it — git-aware, automatic commit messages, the same workflow as Type 2.
Difference from Type 2: Type 2 locks you into one LLM family. Type 3 takes any OpenAI-compatible endpoint with your own API key.
Distinguishing trait: cost-sensitive; multi-provider comparison; self-hosted LLMs (Ollama / vLLM) are fair game.
Good for: experimenting across LLMs; saving cost; local LLMs; not wanting vendor lock-in. Not for: people who find setup intimidating (you manage API keys and provider configs).
*Hermes Agent belongs to both Type 3 (CLI mode) and Type 4 (cloud mode) depending on how you deploy it. More detail below.
Type 4: Cloud-deployed — exemplar: Hermes Agent¶
Exemplar: Hermes Agent (Nous Research, ★ 193k+, MIT)
Hero example: You're on the subway, you open Telegram on your phone, and you message your Hermes bot: "Pull today's arXiv ML papers, give me 3 highlights, send the result back to Telegram." Hermes — running on your $5 DigitalOcean VPS — receives the message, decides to use GPT-5 (paper discovery) + Claude Opus (summary) + Gemini Flash (compression to 3 bullet points), executes the pipeline, and sends the result back. You never touched your laptop.
5 distinctive features:
- Multi-platform chat interface: Telegram / Discord / Slack / WhatsApp / Signal all work as entry points. Whichever platform you ping from is the platform the agent replies on.
- Multi-LLM routing (200+ model neutral): OpenRouter + NVIDIA NIM + Zhipu GLM + Kimi + Xiaomi MiMo + MiniMax + HF + OpenAI + Anthropic + Google. A single conversation can span multiple LLMs.
- 24/7 availability: the agent doesn't depend on your laptop; it lives on a cloud VPS, always reachable.
- Built-in cron: routines like "every day at 9am, do X and send Y" are first-class.
- Self-improving skills (experimental, not yet independently audited): the more you interact, the more the agent generalizes into reusable skills that accumulate across sessions.
Why this type exists: When the agent is a personal assistant rather than a pair programmer, it shouldn't be tied to your laptop. Type 4 turns the agent into a 24×7 service.
Distinguishing trait: ~$5/month VPS hosting + API costs; China-region LLM support (GLM / Kimi) — a useful backup to switch to when US services are flaky.
Trade-offs: - ⚠️ Self-improving skills are a new capability with no independent security audit yet — don't enable it for high-stakes tasks (medical / legal / payments) - You lose IDE/terminal-style direct filesystem manipulation; you adopt a chat-first workflow - You need self-host fluency (Linux / Docker / systemd basics)
Good for: cross-platform notifications; 24/7 routines (daily paper scan / stock-watching / reminders); China-region LLMs; multi-LLM cost optimization; workflows that shouldn't depend on your laptop being open. Not for: pure code writing (Type 2 is more native); people who don't want to self-host; high-reliability production tasks.
Type 5: Edge-deployed — exemplar: OpenClaw / ClawBox¶
Exemplar: OpenClaw (community, Jetson ecosystem) / ClawBox (€549 pre-installed Jetson kit, 67 TOPS)
Hero example: You run a law firm. You need AI to help organize a client's medical records + medical notes + physician testimony into a chronology. But this data absolutely cannot go to the cloud. So you buy a ClawBox (NVIDIA Jetson Orin Nano + OpenClaw + Ollama + Qwen 3.5 7B pre-installed), put it on your firm's network, and SSH in to work with it. All data stays inside this €549 box — zero telemetry, zero API calls, fully auditable.
5 distinctive features:
- Hardware-specific: NVIDIA Jetson series (Orin Nano 8 GB, Thor 128 GB) or Raspberry Pi. GPU-accelerated, edge inference.
- Local LLM only: Ollama backend, running Qwen 3.5 2B-7B / Llama / Mistral / Gemma or other open-weight models. No cloud API calls whatsoever.
- Zero cloud dependency / fully auditable: localhost-bound, works in network-isolated environments, no telemetry.
- Edge-optimized memory: semantic search memory files under 10 MB, persistent cross-session memory (e.g. openclaw-memory-enhancer).
- Physical AI bridge: drives physical devices (robots / sensors / smart home) — the agent works across physical + digital environments.
Why this type exists: When data cannot leave the local machine (medical / legal / defense / privacy-sensitive), cloud-deployed isn't an option. Type 5 puts the agent fully on-device, trading €549 of hardware for 0 cloud cost and 0 data exposure.
Distinguishing trait: one-time hardware investment, then API cost goes to zero; lives inside NVIDIA's edge hardware ecosystem; Jetson Thor can run a 30B model.
Trade-offs: - Model size is bounded by edge hardware (Orin Nano tops out at 7B, Thor at 30B) - Setup is more involved than cloud (you need NVIDIA Jetson familiarity, JetPack, Docker, Ollama) - No 24/7 cross-platform convenience like cloud-deployed
Good for: privacy-sensitive data; offline-first; home AI box (smart home); physical AI (robots); long-term ownership without recurring API bills. Not for: people uncomfortable with Linux / NVIDIA tooling; needing frontier models (GPT-5 / Claude Opus); unwilling to spend €549.
Subagent — “Spawning an Agent Inside an Agent Runtime”¶
The 5 types above describe where the agent runs (IDE / Terminal / any CLI / Cloud / Edge). A subagent is another dimension: while an agent is executing a task, it spawns another agent to handle a subtask.
There are two main implementation paths:
| Path | How it starts | Examples |
|---|---|---|
| Framework-based (Stage 4) | pip install langgraph / crewai / autogen + Python orchestration code |
LangGraph / CrewAI / AutoGen / Swarm / Strands |
| Claude Code native (Stage 5.5) | Write .claude/agents/<name>.md; invoke it from the main session with the Task tool |
Claude Code subagents + Claude Agent SDK |
The difference is runtime ownership: - Framework path: your own Python process runs the orchestrator, and each sub-agent is an object inside your program - Claude path: Claude Code spawns a new agent instance itself; parent / child share the Claude runtime, and the parent only sees the child’s final result (context is isolated automatically)
Which should you choose? If you need to mix LLM providers (GPT + Claude + Gemini) or embed multi-agent orchestration into another application, choose the framework path. If you are already committed to Claude Code and staying inside the Claude ecosystem, choose the subagent path (much less boilerplate).
See the full comparison table at the start of Stage 5.5; to jump straight into 15 daily dispatch recipes → subagent-cookbook.en.md (each includes a scenario + which subagent to use + a copy-paste prompt template).
Cross-paradigm combinations (the power-user pattern)¶
Real power users often run 2 or 3 types simultaneously, each handling what it's best at:
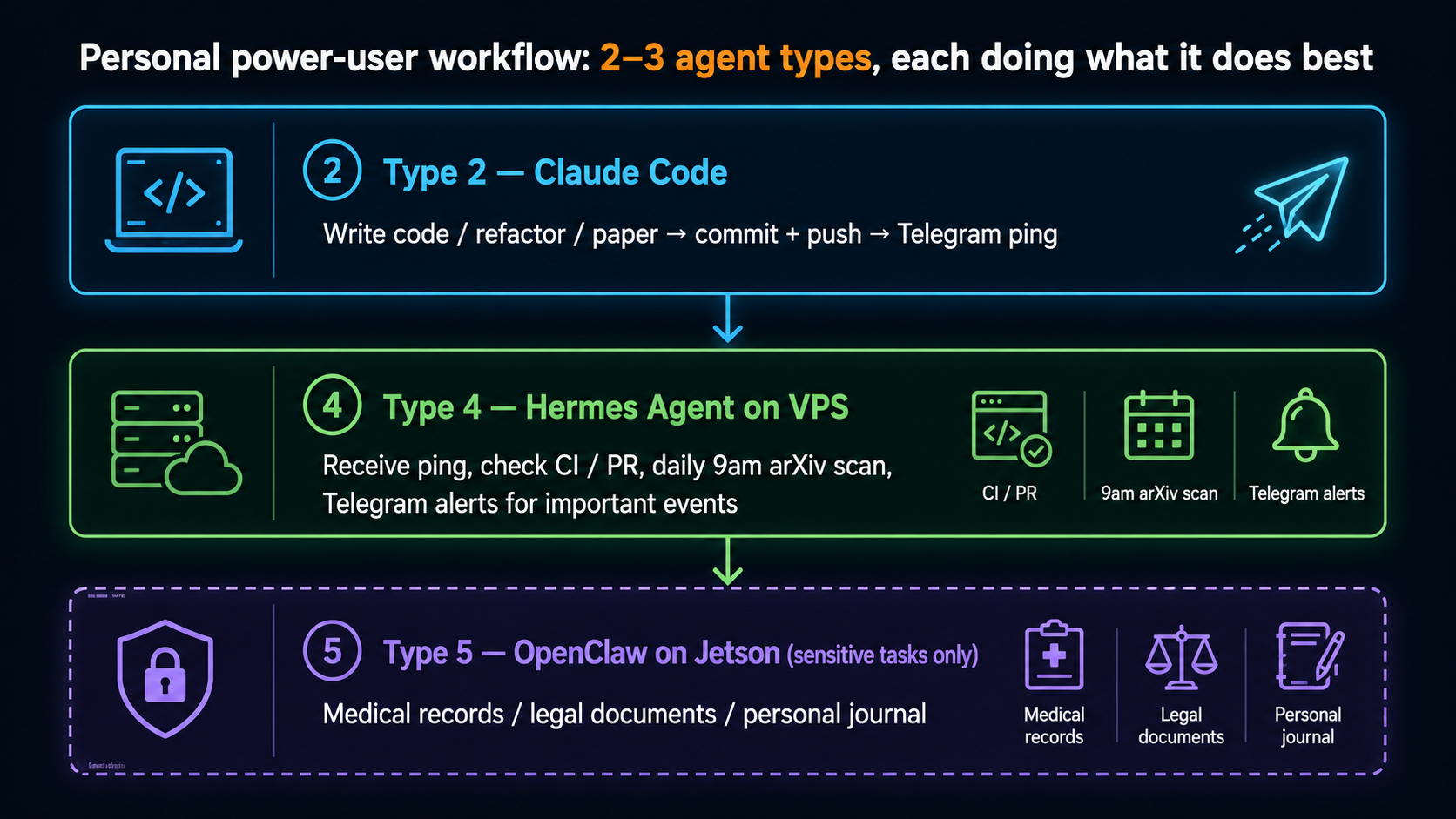
Why this combination: - Type 2 handles code (terminal is the most natural interface) - Type 4 handles routines + cross-platform (works when your laptop is closed) - Type 5 handles privacy (data cannot leave the machine)
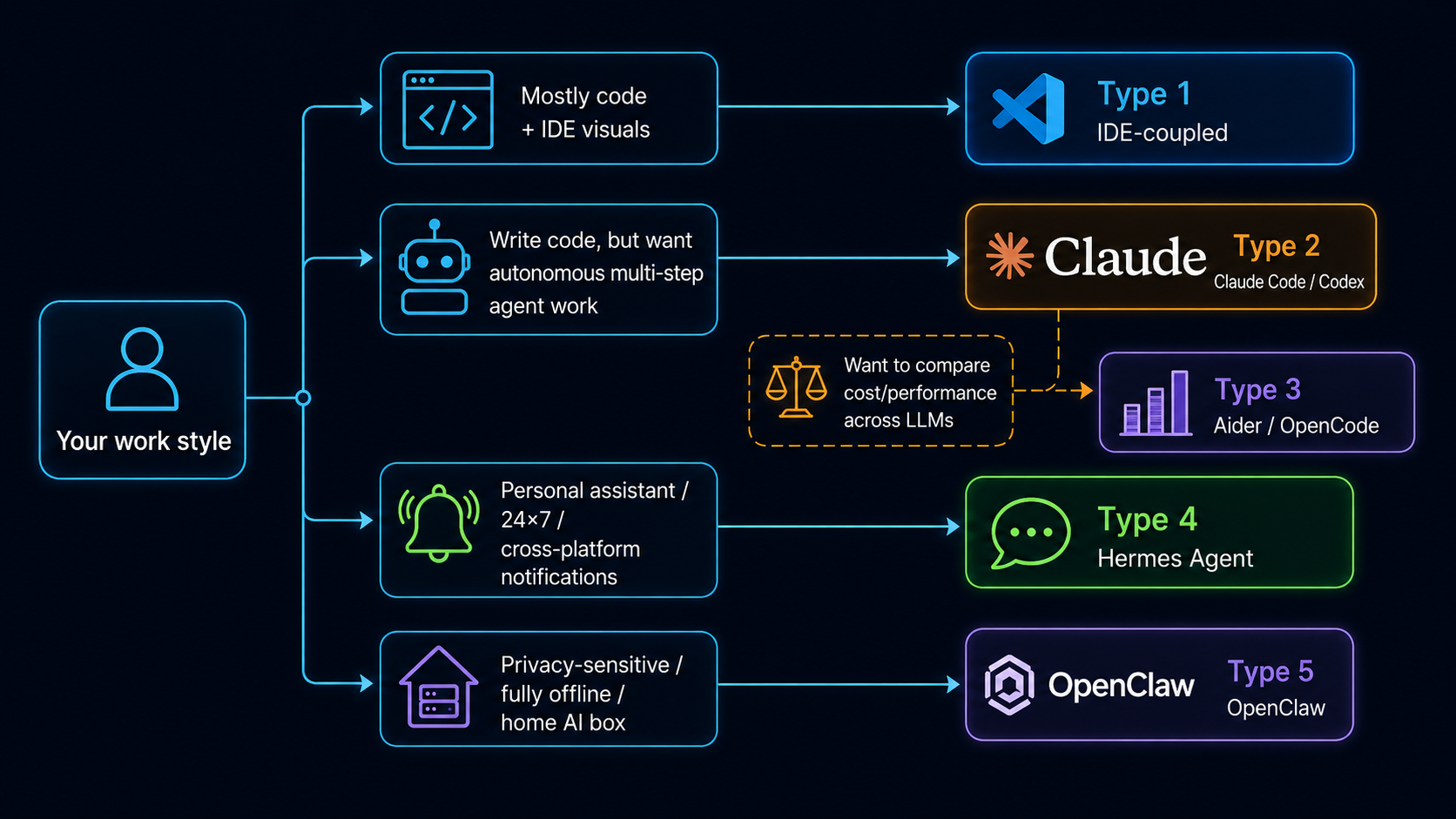
Decision tree (text form)¶
Links to existing stages / branches¶
- Learn Type 2 hands-on → Stage 5: Claude Code Ecosystem
- See the 7-CLI detailed comparison (Type 2 + Type 3) →
resources/cli-agents-guide.en.md - Compare IDE-coupled tools (Type 1) →
branches/for-developer.en.md - Step-by-step Hermes deployment →
resources/cookbook.en.mdRecipe 6 (Hermes + Ollama walkthrough) - Jetson + OpenClaw setup → Jetson AI Lab tutorial + Seeed Studio wiki
How I personally use these¶
- Daily development: Type 2 (Claude Code, subscription)
- Paper monitoring: still manual for now (a weekly arXiv scan by hand) — Type 4 Hermes is on the list to try
- Research vault: Claude Code on my laptop calls the research-hub pipeline (Type 2 mode)
- No Type 5 yet: my data isn't sensitive enough yet to justify going fully offline
Once you try Type 4 or Type 5 in practice, come back and add your own use case to this reference.